
Нейросети засоряют интернет: 7 ситуаций, в которых ИИ делает всем только хуже

Часто ИИ-контент встречается там, где не ожидаешь его увидеть: в фотобанках, поисковой выдаче, отзывах на маркетплейсах.
Как и любой инструмент, нейросети можно использовать не только во благо. Количество созданных с их помощью текстов, изображений, видео- и аудиозаписей уже таково, что это влияет на весь интернет. И не всегда речь о невинных генерациях: массово производят вводящий в заблуждение или попросту некачественный контент.
Расскажу про ситуации, где нейросети уже ощутимо влияют на работу сервисов и уровень доверия к информации.
Ненастоящие картинки в фотобанках
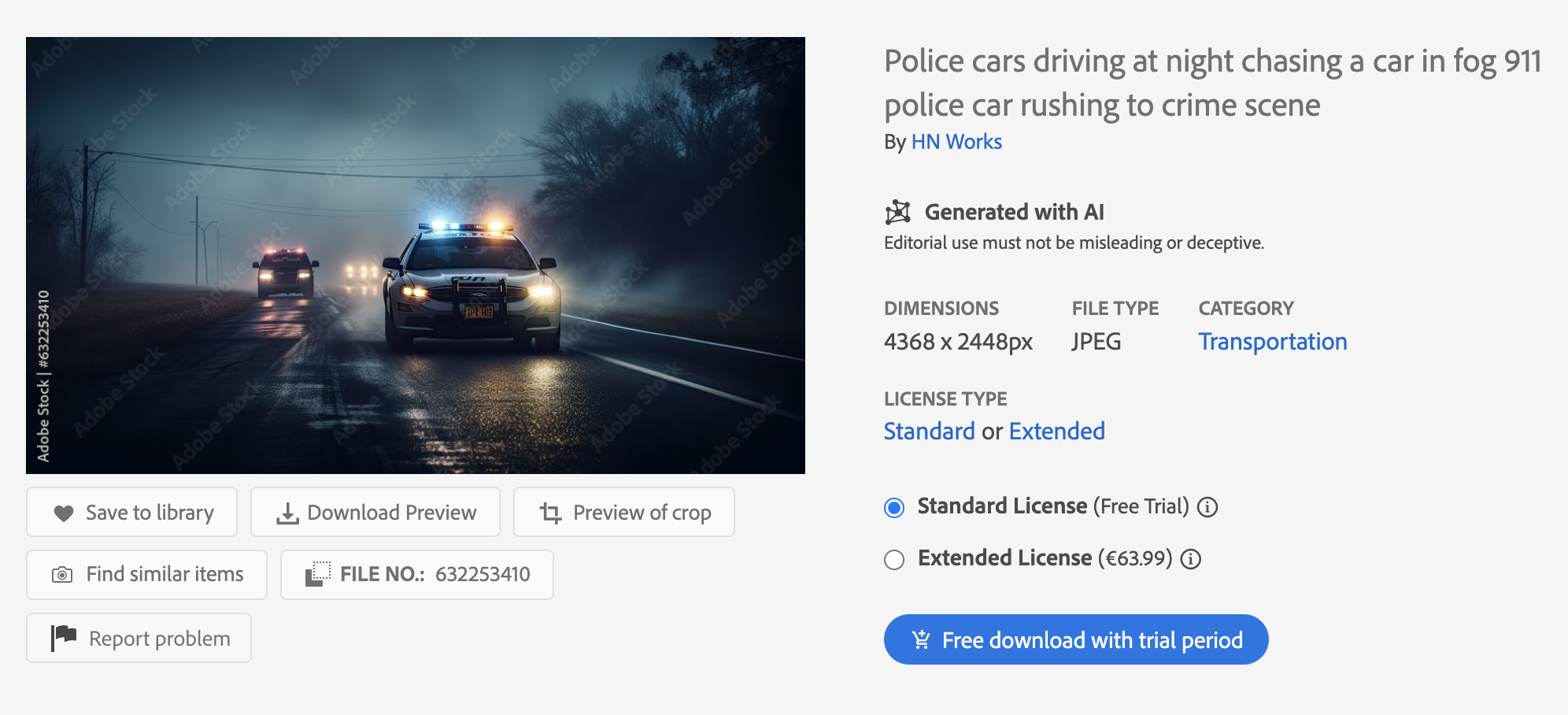
Если на Adobe Stock поискать фотографии по случайному запросу, например с полицейскими машинами, сразу же попадется нейрокартинка. Да, на ней отмечено, что она сгенерирована с помощью ИИ. Однако это не то, что ожидаешь найти в фотобанке, куда пользователи заходят за реальными снимками, которые продаются за деньги.
Хотя картинки помечены и в выдаче, и на странице с полным размером, в потоке легко не заметить отметку. Во всех фотобанках нейроконтент надо маркировать при загрузке: обычно есть галочка AI-generated, Created with artificial intelligence или что-то аналогичное. Но на практике ставят ее не всегда.
Клиенты фотобанков справедливо воспринимают генерации в фотостоках как подделку. Поэтому пытаются распознавать ИИ-картинки на глаз: обращают внимание на перенасыщенные цвета, неправильную анатомию, нереалистичное размещение объектов в пространстве, неверный текст.

Кроме Adobe есть и другие стоковые платформы, которые тоже принимают сгенерированные изображения, например Dreamstime, Freepik, Unsplash, 123RF. А на GettyImages, Depositphotos или Pond5 это запрещено. Но люди все еще могут заливать генеративные картинки, выдавая их за реальные.
Затем такими нейрокартинками СМИ иллюстрируют новости и статьи, в качестве источника указывая фотобанк. Даже если изначально стоковое изображение было помечено как сгенерированное, оно начинает жить в интернете просто как снимок из фотобанка. Вряд ли обычные пользователи пойдут проверять источник на оригинальном сайте.
Баланс пока не найден: понятно, почему фотостоки продают сгенерированный контент, — его легче производить, чем делать реальные фото. Но при этом компании теряют доверие клиентов и попадают в скандалы с фейками.

Ненастоящие картинки в поисковой выдаче
Нейросети начинают искажать поисковую выдачу. Если попробовать поискать в Гугле «пейзаж Исландии», «современный интерьер», «дизайнерскую мебель», многие результаты будут сгенерированными. На первый взгляд понять, что в выдачу просочились нейрокартинки, сложно — приходится присматриваться к деталям.
«Гугл» включил в стандарт метаданных изображений поля для ИИ-работ. Планируется, что в поисковой выдаче сгенерированные картинки будут помечены. А если пользователь ищет именно фото, ему их не покажут. Также разрабатывают инструменты, которые будут распознавать нейроконтент и маркировать его самостоятельно. Но все это пока не работает.
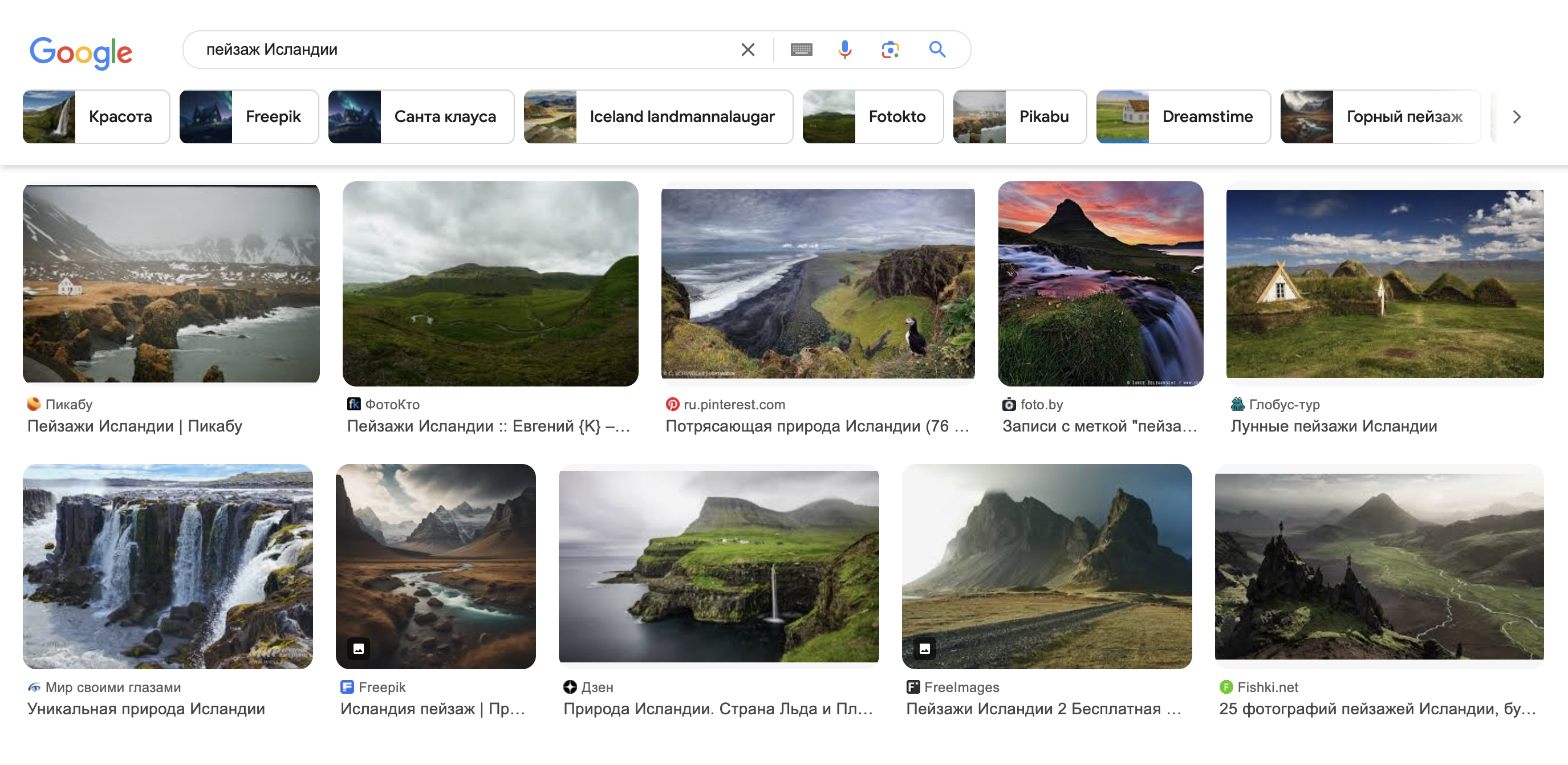
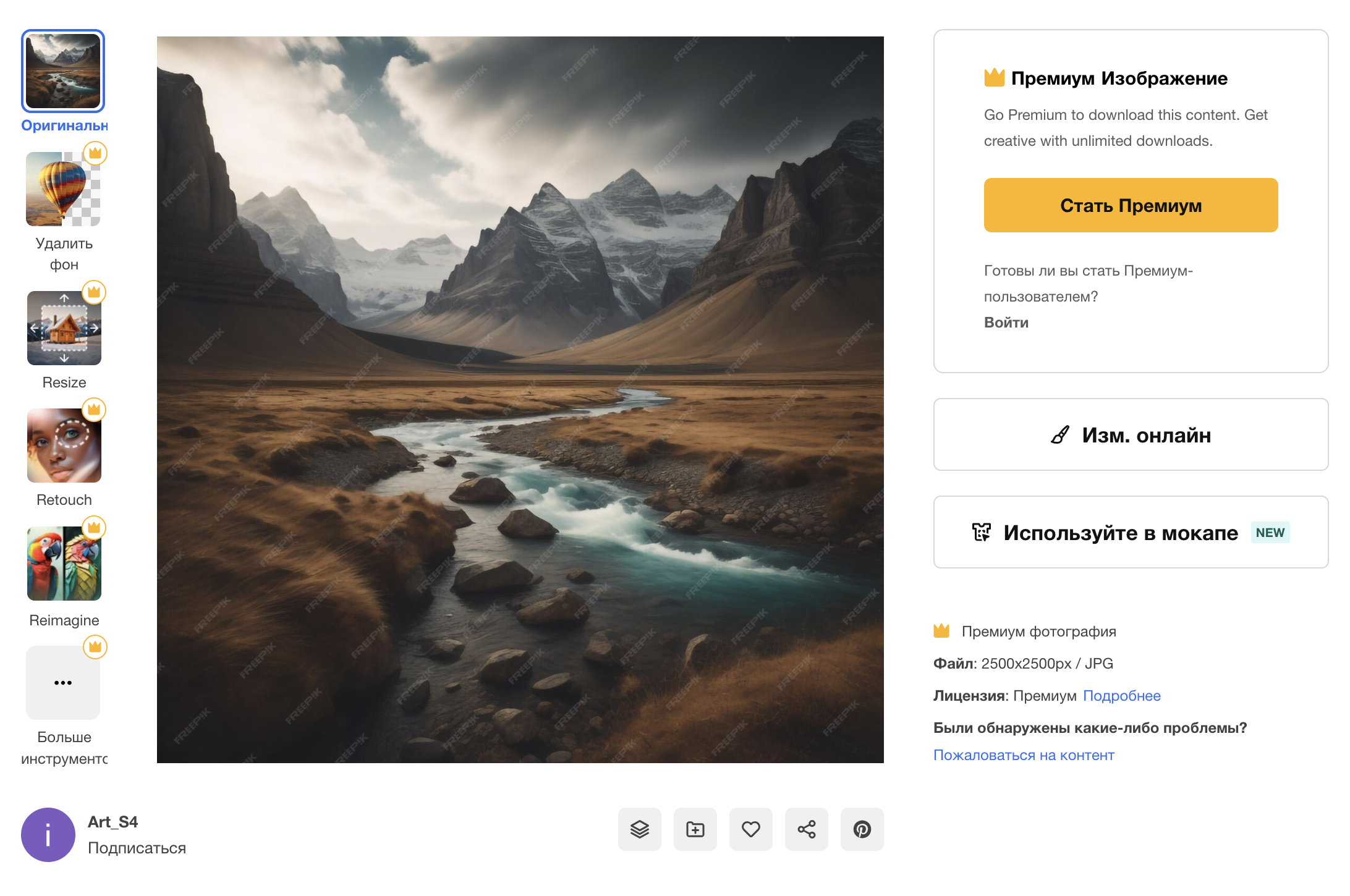
К тому же это никак не решает проблему: если по запросу «современный интерьер» я хочу получить выдачу не из генеративных картинок, а реальные рендеры от дизайнерских студий, то нужно указывать «современный интерьер, рендеры, созданные людьми»? Это превращает поиск в интернете в абсурд.
Бывают и более серьезные случаи, когда поисковая выдача может переписывать историю. Так, в октябре 2023 года по запросу «неизвестный бунтарь» в Гугле первой картинкой появлялось сгенерированное селфи мужчины на фоне танков. Такого фото никогда не существовало. Причем изображение запостил пользователь Reddit в разделе, посвященном Midjourney — то есть его не пытались выдавать за реальное. После того как новость разошлась в СМИ, сервис исправил ошибку.


Ненастоящие тексты в блогах и статьях
Многие сайты и блоги начали использовать нейросети для создания контента, особенно в нишах с высокой конкуренцией. Если погуглить популярные кулинарные сайты, то легко наткнуться на площадки, где все тексты и иллюстрации созданы нейросетями — они даже вырвались в лидеры в англоязычном сегменте интернета. Статьи написаны ChatGPT по одной и той же незатейливой структуре, картинки сгенерированы в Dall-E.
Цель — вывести сайт в топ поисковой выдачи. А будет ли написанное полезно пользователям — как повезет. Хорошо, если люди редактируют эти тексты. А если нет, то туда легко может попасть ложная, непроверенная или вредоносная информация.
SEO-тексты пишут исключительно ради ключевых слов — это проблема интернета уже лет двадцать. Но теперь многие генерируют такие статьи дешево и быстро, не приоретизируя качество и содержание. Кроме того, нейросети позволяют автоматически производить не самые достоверные тексты вроде гороскопов.

Тексты из нейросетей уже влияют на качество доступной и достоверной информации в интернете в целом. В 2023 году объем сгенерированных текстов в поисковой выдаче Гугла оценивали в 10%. Можно предположить, что процент будет только возрастать. К тому же генеративные тексты выходят и за пределы интернета: работы из ChatGPT не раз публиковали в научных журналах.
Cами нейросети обучаются на информации из интернета — получается замкнутый круг. Это может привести к еще большему снижению качества контента, так как ошибки и неточности будут многократно воспроизводиться. В итоге интернет заполнится однотипными и поверхностными материалами.

Ненастоящие новости
Обычно от новостных сайтов ожидают достоверной информации. Там встречается много контента с фото- или видеоподтверждениями, некоторые сразу вызывают эмоциональный отклик. Однако громкие новости могут оказаться неправдой.
Популярные примеры инфоповодов, контент для которых генерировали в нейросетях, — Папа Римский в пуховике Balenciaga, звонки Джо Байдена, призывавшего игнорировать праймериз, мошеннические сборы на помощь пострадавшим после землетрясения в Турции. Все это быстро опровергли мировые СМИ с репутацией.

Еще в мае 2023 года в The Guardian писали минимум о 49 новостных сайтах с полностью сгенерированным контентом. Это только те, на которых встречались автоматические сообщения вроде «I cannot complete this prompt» или «as an AI language model». Обычно эти фразы встречаются в ответах нейросетей, когда они не могут выполнить запрос или указывают на ограничения. В реальности таких сайтов куда больше, если авторы подчищают ошибки в текстах за нейросетями.
Ловят на публикации сгенерированных текстов даже солидные издания с серьезной репутацией. В 2023 году скандал затронул Sports Illustrated — американский журнал с 70-летней историей. На сайте издания обнаружили написанные с помощью нейросетей обзоры, которые заказывали у стороннего подрядчика. Тот работал также со многими другими газетами и порталами.
Такие новости, с одной стороны, снижают доверие к любой информации вообще, а с другой — позволяют манипулировать общественным мнением. Это очень заметно, например, в период выборов в разных странах.

Ненастоящие товары в рекламе
Сгенерировать тысячи иллюстраций для рекламных целей гораздо проще, чем отрисовать их или сделать и обработать фото. В некоторых случаях это не вызывает этических споров: например, в рекламе услуг или учебных курсов картинка служит для привлечения внимания и может быть более или менее произвольной. Однако сгенерированные изображения используют и в рекламе товаров — там, где пользователь рассчитывает увидеть настоящее фото.
К примеру, рестораны формата дарк-китчен в американских службах доставки DoorDash и Grubhub ставят нейроарт на карточки с хот-догами. Что приедет клиенту, неизвестно. Да, часто компании обрабатывают фото фастфуда, чтобы в рекламе он выглядел лучше, чем в реальности, — но все же эти снимки хотя бы основаны на сфотографированных хот-догах.
А бывает, что товар вообще не совпадает с картинкой, если сервисы доставки ставят на лот с газировкой «Спрайт» сгенерированное изображение яблочного мартини, а на рулетики с ветчиной — странное месиво из мяса и хлебных палочек. Это даже не введение в заблуждение, а откровенный обман клиента.

Ненастоящие музыканты в стримингах
Представьте: вы слушаете плейлист с новинками в Spotify, понравилась песня, хочется узнать об артисте. И обнаруживаете, что музыканта не существует: фотографий нет, описания в стриминге и никакой информации в интернете тоже. На Reddit считают, что такие треки генерируют в нейросети Suno AI.
Чаще всего они попадаются в плейлистах с инструментальной музыкой для работы или спорта. Их легко распознать: они звучат похоже, на аватарках артистов стоят обложки их же альбомов, в описании нет текста и ссылок на соцсети, а выкладывать треки они начали в 2023—2024 годах.

У артистов Awake Past 3 и Gutter Grinders, которых, предположительно, не существует, сервис даже ставил синюю галочку «Подтвержденный исполнитель», хотя сейчас их треки удалены с платформы.
При этом Spotify признавал проблему. В 2023 году компания удалила десятки тысяч песен, созданных нейросетями. Для накрутки счетчиков прослушиваний тоже использовали ботов. А в сентябре того же года пользователи жаловались, что почти весь плейлист Radar с новинками от начинающих музыкантов был забит сгенерированным контентом — на это сервис уже не отреагировал.
В манипуляциях со сгенерированной музыкой в плейлистах подозревают сам Spotify, потому что, предположительно, ненастоящие артисты часто встречаются в популярных плейлистах с миллионами сохранений. Логика простая: c помощью сгенерированной музыки компания может не выплачивать роялти за прослушивания настоящим музыкантам, а оставлять деньги себе.

Ненастоящие отзывы
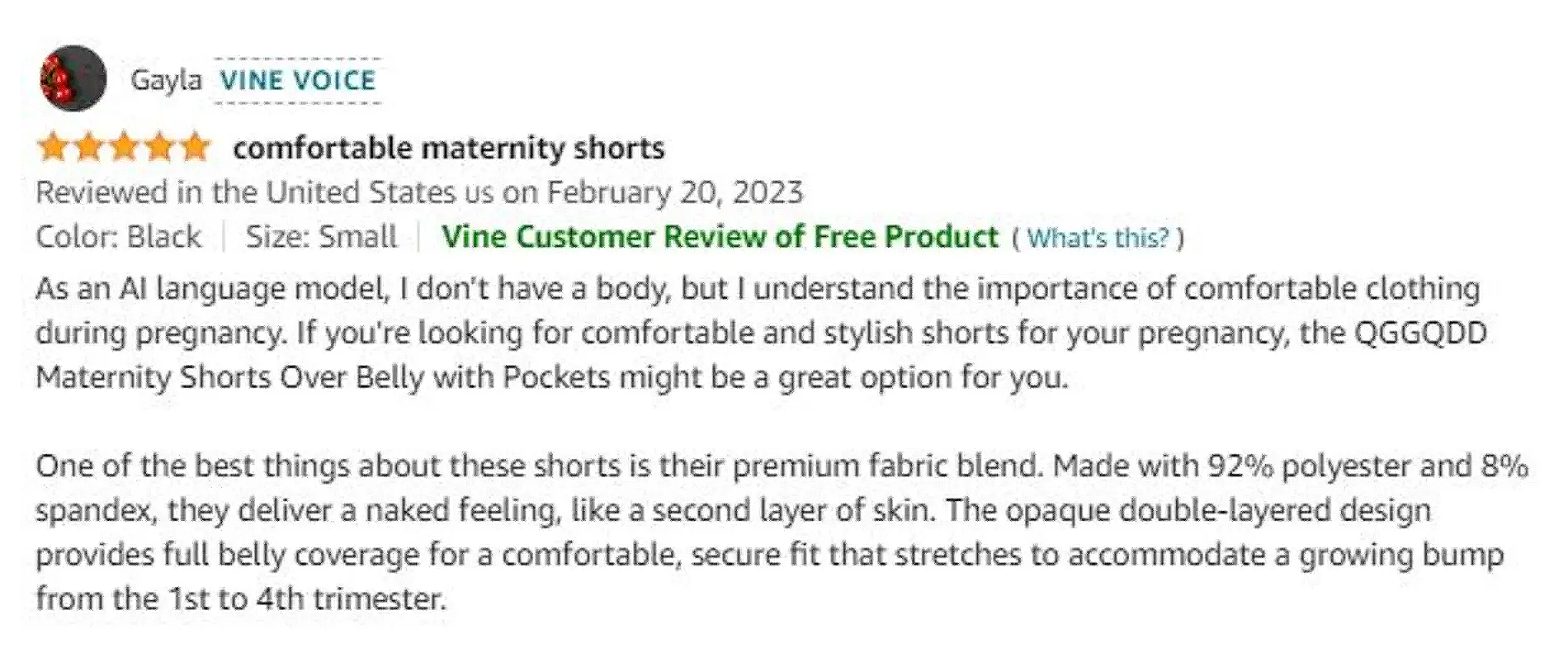
Заказывать или бронировать через интернет — всегда риск. Принять решение помогают отзывы на товары, отели или рестораны. Однако если это все сгенерировано ИИ, никакой пользы не вынести. Вбросы автоматически написанных отзывов и обзоров в соцсетях на сайтах с оценками и на страницах интернет-магазинов стали массовыми еще несколько лет назад, но с появлением нейросетей производить их стало проще.
Раньше ненастоящие отзывы можно было легко распознать по чрезмерной похвале — они казались рекламными и приукрашенными. ChatGPT пишет правдоподобнее. Хотя текст все еще может казаться формальным и несколько «механическим», с короткими предложениями и странным выбором слов, эти особенности уже не так очевидны для большинства пользователей. ИИ умеет подражать обычному стилю, создавая впечатление, что отзыв написан реальным человеком, который был краток в своих высказываниях.

Доходит и до создания дипфейков знаменитостей, которые якобы рекомендуют разные товары. Тому Хэнксу уже приходилось объяснять, что он не пьет БАДы, а все рекламные отзывы с ним — подделка. Ранее распространяли сгенерированные аудиозаписи с голосом звезды кантри Люком Комбсом, который якобы похудел на чудодейственных жевательных конфетах и всем их рекомендовал.
Федеральная торговая комиссия США пыталась выработать новые правила с 2022 года. В августе 2024 процесс завершился. Теперь компаниям прямо запрещено использовать отзывы от тех, с кем она на самом деле не взаимодействовала, в том числе сгенерированные нейросетями. Получится ли это применять в реальности, пока неизвестно.
Мы постим кружочки, красивые карточки и новости о технологиях и поп-культуре в нашем телеграм-канале. Подписывайтесь, там классно: @t_technocult




















