Нейросети генерируют музыку: как это работает и где попробовать самостоятельно


Нейросети уже впечатляюще генерируют тексты и картинки, а теперь пришло время музыки.
В 2024 году нейросети могут писать треки с нуля по текстовому запросу, дополнять готовые мелодии, предлагать не только музыку, но и слова — и исполнять их разными голосами.
Рассказываем, что происходит в индустрии и где уже сейчас можно попробовать сгенерировать трек самостоятельно.
Как нейросети создают музыку
Музыкальные нейросети обучают на большом объеме аудиофайлов. Их собирают в базу и передают ИИ. Первые результаты будут звучать плохо, но чем больше нейросеть обучается, тем лучше становится звук.
Выучив шаблоны разных композиций, нейросеть может писать похожие мелодии. Многое зависит от базы данных: если обучить ИИ на музыке Элвиса Пресли, то нейросеть будет генерировать только нечто похожее на его песни.
Генерация нот. Обычно нейросети создают музыку в виде последовательности символов. В таком случае результатом генерации будет партитура — последовательность звуков, нот, аккордов. То есть нейросеть создает визуальную репрезентацию композиции и затем ее воспроизводит.
Этот подход OpenAI использовала в нейросети MuseNet, которая вышла в апреле 2019 года. Ее обучили на большом массиве записей, поэтому она может генерировать композиции и комбинировать разные жанры. Например, способна исполнить Симфонию № 5 Бетховена в стиле Леди Гаги.
Такой подход ограничен: нейросеть генерирует только ноты, а не разнообразие человеческих голосов, тональностей, выразительности и тонкостей звука, которые важны для музыки.
Генерация аудиосигнала не имеет ограничений символьных генераторов: такие алгоритмы могут создавать любой звук — разнообразный вокал, аудиоэффекты, переходы, а не только последовательность нот. Это требует больших вычислительных мощностей для обучения модели.
Проблема в том, что музыка состоит из длинных последовательностей. К примеру, четырехминутная песня в студийном качестве состоит из десятка миллионов значений. Это останавливало разработчиков от создания нейросетей, способных генерировать музыку «с нуля».
Что музыкальные нейросети умели раньше
Генерировать музыку по шаблонам. В последние годы появились инструменты, генерирующие музыку по жанрам или настроениям. Они позволяют безо всяких познаний в музыке за несколько секунд создать трек, а затем поменять в нем инструменты или мелодию.
Но контроля над результатом генерации в таких сервисах мало: любой запрос задать не получится, приходится работать с готовыми пресетами.
Разделять дорожки. С помощью нейросетей также научились чисто разделять дорожки в треках: например, чтобы удалить вокал или переместить бас из одной песни в другую. Это упростило создание ремиксов и мэшапов.
Раньше приходилось получать доступ к исходникам треков или глушить частоты, а теперь это делается через программы, например Serato Stems 3.0 или Аudioshake. Эти инструменты помогают диджеям и продюсерам, работающим с семплами.
Создавать бесконечные музыкальные фоны. ИИ также может генерировать фоновую музыку. Например, стартап Endel выпустил приложение, которое в реальном времени создает бесконечные звуковые ландшафты, чтобы слушатель мог сосредоточиться на работе или учебе. Похожий сервис выпустил и «Яндекс». Такая музыка обычно звучит как эмбиент или лоу-фай хип-хоп.
Что музыкальные нейросети умеют теперь
В начале 2023 года исследователи из Google представили нейросеть MusicLM, которая может генерировать аудио продолжительностью до пяти минут напрямую.
Алгоритм сжимает аудио, отбрасывая биты информации, не имеющие отношения к восприятию музыки. Затем звук генерируется в этом сжатом пространстве, а на выходе перекодируется в нормальное аудио.
MusicLM обучена на 5500 парах аудио с соответствующими текстовыми описаниями. Всего нейросети «скормили» 280 000 часов аудиозаписей. ИИ нельзя попробовать самостоятельно, но компания представила примеры генерации.

Генерировать музыку по описанию — основная функция MusicLM. Она создает треки как по короткому запросу, например «мелодичное техно» или «клуб в 80-х», так и по описанию на целый абзац.
К примеру, MusicLM создала аудио по такому текстовому описанию: «Саундтрек аркады в быстром темпе и с бодрым ритмом с запоминающимся рифом электрогитары. Музыка повторяется и легко запоминается, но в ней присутствуют неожиданные звуки — удары тарелок или барабанная дробь».
Это уже можно попробовать?
Google не планирует открывать публичный доступ к MusicLM из-за возможных проблем с авторским правом — ведь ИИ обучали на музыке, принадлежащей реальным исполнителям. Нейросети, которые генерируют картинки, уже столкнулись с такой проблемой: против Midjourney и Stable Diffusion подали иски художники, на чьих работах обучили эти сервисы. Однако компания выпустила базу данных, на которой разработчики смогут обучить свои нейросети.
Нейросеть также может создавать музыку по скрипту: разработчики сгенерировали аудио, которое начинается как «медитация», переходит к «пробуждению», а затем к «пробежке». Так можно описать любую историю, а нейросеть сделает переходы в указанных тайм-кодах.
Генерировать музыку по вокалу может сервис SingSong, который компания Google создала на основе MusicLM. Он работает как караоке наоборот: обычно люди поют под трек, но в этом случае песня создается на основе голоса.
Разработчики говорят, что сервис позволит любому человеку, умеющему петь, создавать новую музыку с богатым инструментарием. Сам алгоритм пока нельзя попробовать, но можно послушать примеры генерации.
Генерировать звуковые эффекты умеет другая нейросеть — AudioLDM, использующая модель скрытой диффузии. На ее основе работает Stable Diffusion. Текстовый запрос кодируется предварительно обученной языковой моделью. В зависимости от того, что указано в запросе, модель генерирует сжатый сигнал с помощью диффузионного генератора, который затем преобразуется в звуковую волну.
Нейросеть нельзя попробовать самостоятельно, но компания представила примеры генерации. Так, AudioLDM сгенерировала голос человека под водой, сражение космических кораблей, мяуканье кота, звук проезжающего автомобиля.

Причем AudioLDM улавливает тонкости материалов: звук нарезки помидоров на деревянной доске отличается от звука нарезки картошки на металлическом столе. AudioLDM также генерирует звук по спектрограммам.
Какие музыкальные нейросети можно попробовать уже сейчас
Одни разработчики, например Google и AudioLDM, не планируют открывать доступ к своим моделям. Другие, в том числе OpenAI, выкладывают код на GitHub, который не смогут попробовать люди без знаний программирования. Но некоторые сервисы для генерации музыки доступны всем, в том числе бесплатно. Вот какими уже можно пользоваться самостоятельно.
Suno. По текстовому запросу может сгенерировать мелодию, песню со словами на десятках языков и с даже обложкой для ролика. Или пропоет любой ваш текст, а голос подберет сам или будет следовать запросу. Текстом размечаются куплеты, припевы, инструментальные проигрыши, стиль, паузы и еще десятки параметров.
Бесплатно дают 50 токенов — хватит на пять запросов по два варианта трека в каждом. Но часто добавляют еще: в честь новой версии, в качестве извинения за сбой и по другим поводам. В Т—Ж есть подробная статья о том, как генерировать песни в Suno AI.
Udio. Тоже умеет создавать треки со словами и музыкой по текстовому запросу, писать песни на заданные пользователем слова, а с платной подпиской — редактировать отдельные фрагменты. Можно настраивать десятки параметров, создавать композиции длиной до 15 минут, дописывая по 32 секунды за каждую генерацию. Udio учитывает контекст, поэтому продолжения получаются органичными.
В числе прочего нейросеть знает много русского рока — это удобно, когда задаете стиль своего будущего шедевра. Бесплатно дают 10 кредитов в день — это пять запросов по два варианта трека на каждый — и 100 кредитов в месяц дополнительно.
So-vits-svc. Китайская нейросеть умеет очень реалистично копировать голоса известных исполнителей. С ее помощью, например, сделали популярный трек Heart On My Sleeve со сгенерированными голосами Дрейка и The Weeknd, который потом пришлось удалять со всех площадок.
Нейросеть не генерирует музыку и голос с нуля. для создания нужна оригинальная а капелла, дорожка с минусом и файл с голосом выбранного исполнителя. Мы подробно рассказывали о том, как создать свой трек с помощью so-vits-svc.
Riffusion. Создает короткие 12-секундные треки, которые затем можно разделить на аудиодорожки: голос, барабаны, бас и прочее — и затем скачать, вместе или по отдельности. для генерации трека достаточно ввести 5—20 слов, если надо — попросить нейросеть дописать текст. Затем указываете жанр, стиль, пожелания к вокалу — или просите сервис подобрать все самостоятельно. И получаете три семпла. Их можно скачать как аудио или видео — обложку сайт тоже сгенерирует сам.
Stable Audio 2. Генерирует инструментальные треки: слова и исполнение голосом не предусмотрены. Понимает текстовые запросы, загруженные в качестве референса образцы, плюс есть готовые пресеты: техно, музыка для дома, барабанное соло и другие. Модель обучали на лицензированных данных, то есть с правами на созданные треки проблем не будет. Это позволяет использовать Stable Audio для коммерческих целей. Бесплатно можно сгенерировать 10 композиций в месяц.
Magenta. Набор демоинструментов и мини-игр, созданных на основе открытого кода проекта Google, который занимается машинным обучением. Практического применения у них нет, они просто демонстрируют возможности машинного обучения. Например, MidiMe создает музыку на основе загруженного трека.
Есть и более фановые инструменты: в Runn уровни игры генерируются на основе играющего трека, в Sornting нужно составлять мелодии в интерполяцию, а Piano Genie позволяет почувствовать себя пианистом.
Mubert. Сервис специализируется на генерации фоновой музыки для роликов на «Ютубе» или коротких рилсов, а также джинглов и миксов, а в запросе можно использовать и текст, и картинку. Можно выбирать из предложенных жанров и настроений, например чиллвейв или эмбиент. Иногда генерация занимает продолжительное время.
После регистрации бесплатно можно сгенерировать до 25 треков в месяц длительностью до 25 минут. Чтобы их скачать, нужно добавить ссылку на канал, где вы будете их использовать.
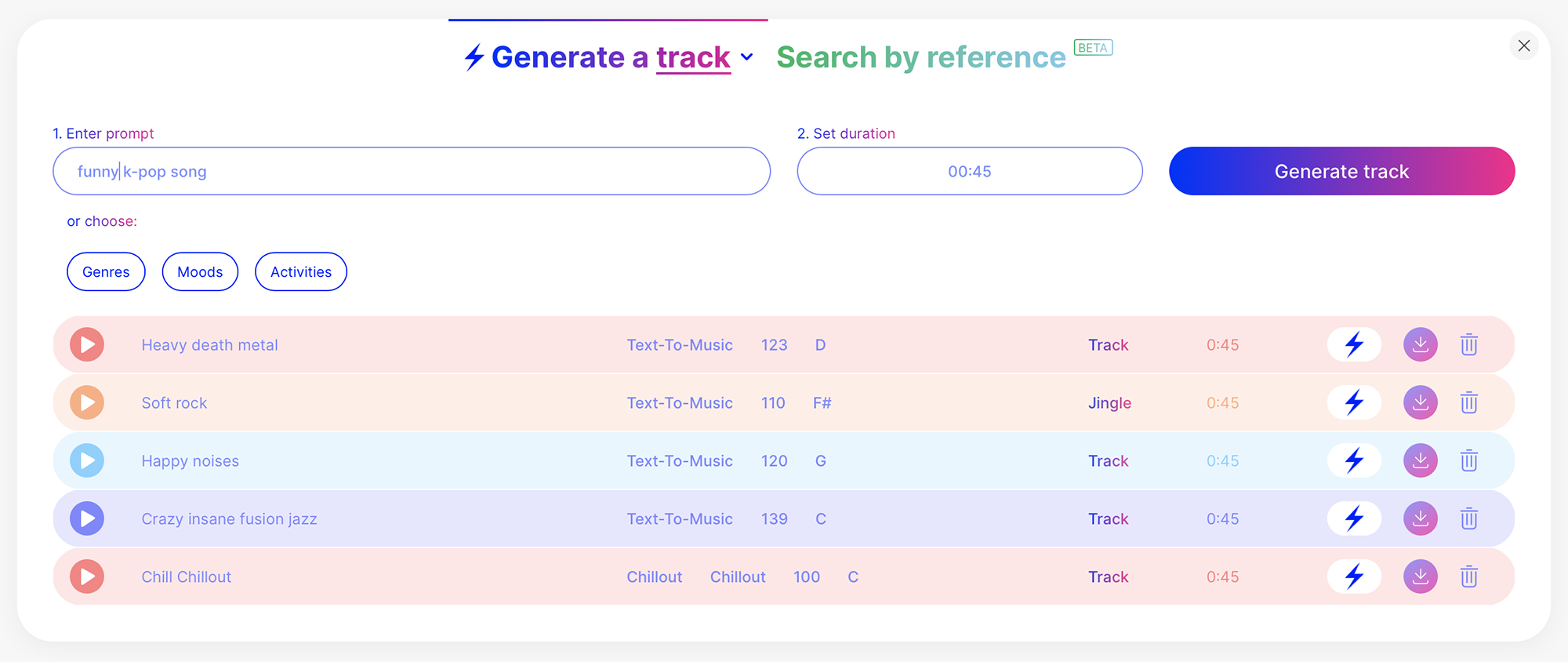
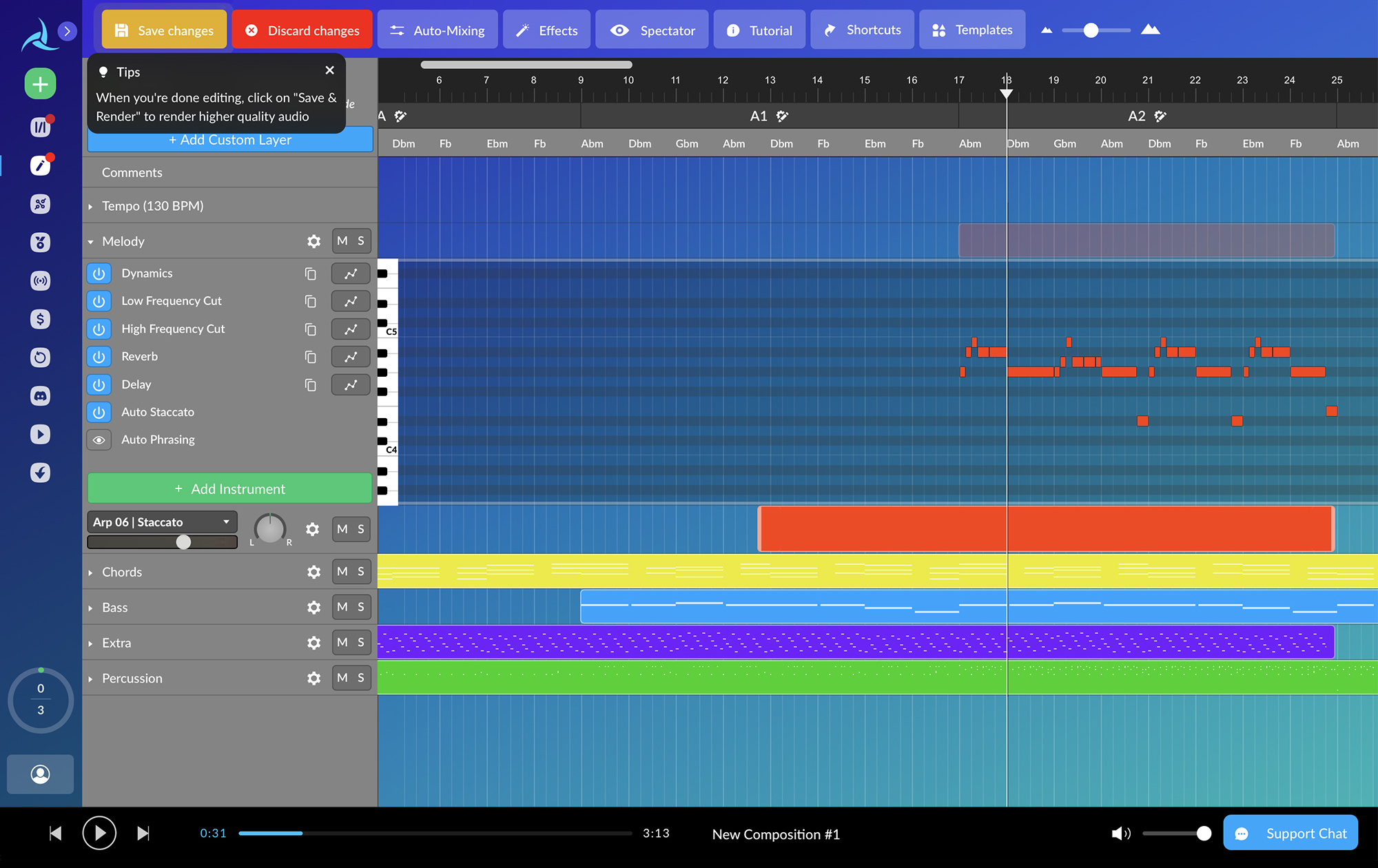
Avia.AI. Генерирует музыку в выбранной тональности по заготовленным жанрам или загруженному треку. Трек можно отредактировать прямо в сервисе — удалить или добавить инструмент, растянуть или сжать партию, изменить темп, добавить реверб или дилэй.
Бесплатно можно скачать три трека длительностью до трех минут. Чтобы скачивать до 200 треков и получить на них авторские права, придется платить 49 € (3860 ₽) в месяц. Такую музыку можно использовать в фильмах, сериалах или видеоиграх, а не только для роликов на «Ютубе».
Мы постим кружочки, красивые карточки и новости о технологиях и поп-культуре в нашем телеграм-канале. Подписывайтесь, там классно: @t_technocult