Нейросети для генерации видео: 4 бесплатных сервиса

Нейросети уже умеют генерировать видеоролики.
Да, пока еще не так хорошо, как текст или картинки. У нейросетей для генерации видео есть серьезные ограничения: они не могут создать ролик длиннее нескольких секунд, а уровень реализма пока далек от какого-нибудь Midjourney. Сгенерировать одну хорошую картинку — уже непросто. А в видео надо не только создавать множество кадров, но и сделать так, чтобы они соотносились друг с другом.
Но можно оценить возможности сервисов. Расскажу про четыре нейросети, которые помогут сделать видео уже сейчас.

Как писать запросы для нейросетей, генерирующих видео
Почти каждый сервис предлагает написать текстовый запрос — то есть описать результат, который вы хотите получить. Ютубер Theoretically Media придумал схему для промптинга, которая подходит для большинства нейросетей, генерирующих видео. Вот как она выглядит:
Стиль — камера — объект — действие — окружение — освещение.
В каждом параметре нужно указать по одному слову или фразе и выстроить из них цепочку. Это и будет промпт. Вот какие слова можно использовать:
- Стиль: cinematic action (сцена из фильма), animation (анимация), black and white film (черно-белая пленка).
- Положение камеры или тип объектива: wide angle (широкий угол), close up (крупный план), long shot (общий план).
- Объект: woman with red hair (рыжая женщина), siamese kitten (сиамский котенок), lonely house (одинокий дом).
- Действие: walking (идет), smiling (улыбается), rolling (катится).
- Окружение: rooftop (крыша), medieval castle (средневековый замок), cityscape (городской пейзаж).
- Освещение: sunset (закат), warm lighting (теплый свет), moonlight (лунный свет), studio lighting (студийный свет).
Чтобы не тратить бесплатные генерации впустую, при написании запросов стоит учитывать ограничения сервисов. Вот с чем нейросети еще плохо справляются:
- Ошибаются в сложных действиях — драках, перекатах, полетах и другом экшене. Нейросети умеют рисовать простые действия: «смотрит в сторону», «бежит», «говорит».
- Не умеют создавать крупный план. В большинстве сервисов получаются пугающие результаты. Камера выставляется настолько близко к объекту, что сложно представить, для чего подобное можно использовать.
- Не могут генерировать реалистичных людей. Если вам нужен ролик с человеком, то загрузите свою картинку — сгенерированную в нейросетях или фотографию. А чтобы видео приблизилось к реализму, добавьте в запрос слово «гиперреализм» — hyperrealistic.

Скорее всего, нереалистичное изображение людей — вопрос времени. Создатели Midjourney за пару лет отучили нейросеть рисовать лишние пальцы, а Firefly от Adobe вовсе способна генерировать картинки, которые не отличить от стоковых фото.
Для честного сравнения я протестировала все нейросети на трех одинаковых запросах:
- Окружение: cinematic, long shot, chilly winter day, lonely village, dusk — одинокая зимняя деревушка в сумерках.
- Реалистичный портрет человека: cinematic action, long shot, beautiful bartender girl pouring a drink, bar, warm lighting — кадр из фильма, девушка-бармен наливает напиток, теплый свет.
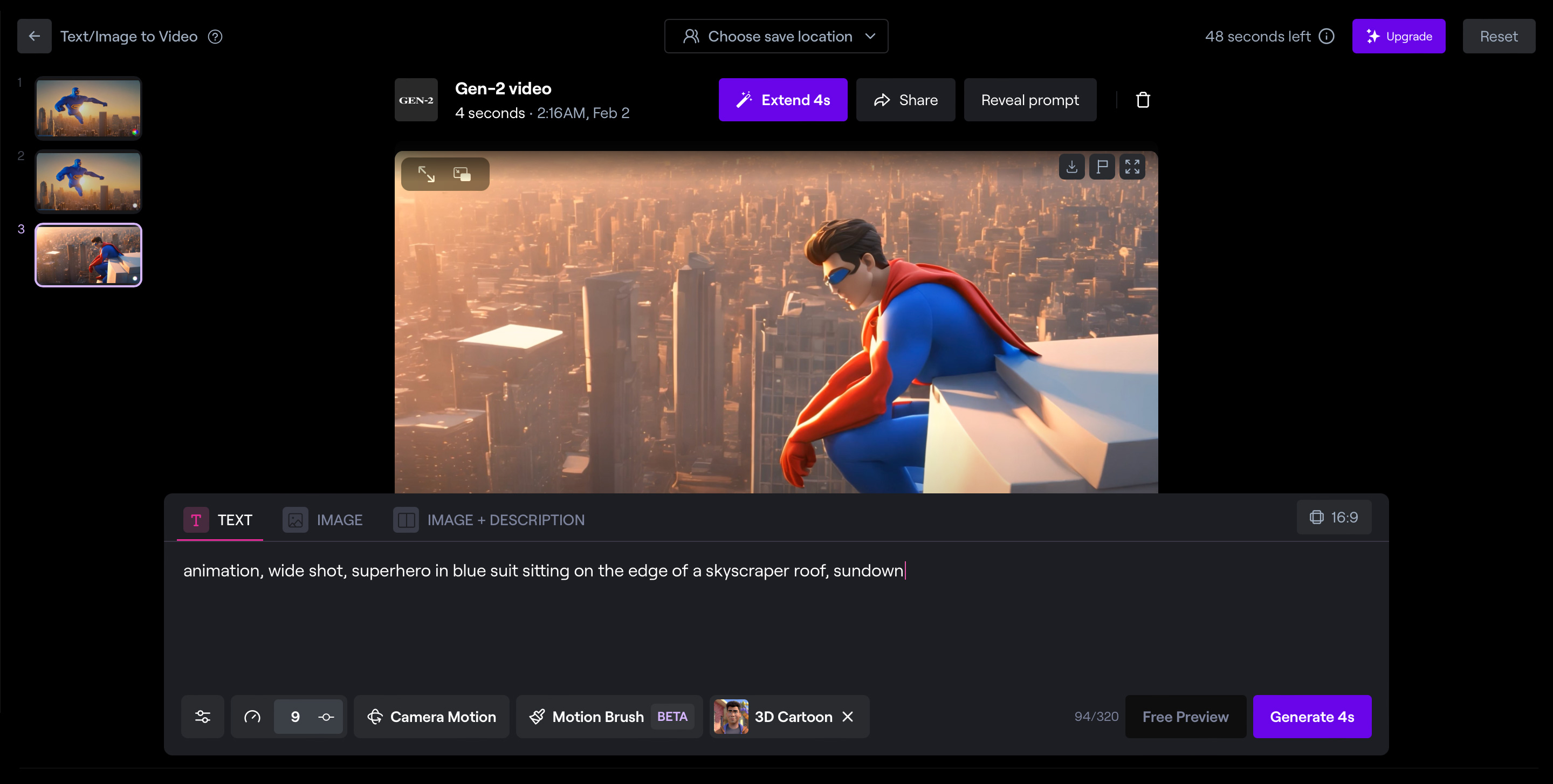
- Мультяшный экшен: animation, wide shot, superhero in blue suit jumping from a roof of a skyscraper, sundown — анимация, широкоугольная камера, супергерой в синем костюме прыгает по крышам небоскребов на закате.
Что умеет: генерирует видео по текстовому запросу, по картинке или по запросу и картинке
Поддерживает ли русский язык: нет
Сколько бесплатных попыток: 105 секунд видео на один аккаунт
Что дает подписка: больше генераций, улучшение качества и экспорт без водяного знака от 12 $ (1085 ₽) в месяц, оплатить с российской карты нельзя
В каком формате экспортирует: MP4
Вторая модель Runway — самая продвинутая среди доступных широкой публике нейросетей для видео. Она хорошо рисует переходы между кадрами, особенно при анимации картинок и фотографий. Изображение «штормит» заметно меньше, чем у других сервисов. А еще у нее есть режим, с которым можно генерировать серию видеороликов с похожим визуальным стилем.
Как пользоваться. Генерация видео здесь расходует кредиты — по пять за каждую секунду. За регистрацию нового аккаунта Runway дает 125 кредитов и еще 400 бонусных кредитов в честь выхода Gen-2. Всего получается 105 бесплатных секунд видео.
Кредиты не сгорят спустя время, но и восполняться тоже не будут. Ежемесячно лимит обновляется только с платной подпиской. Чтобы получить новые бесплатные попытки, придется регистрировать новый аккаунт.
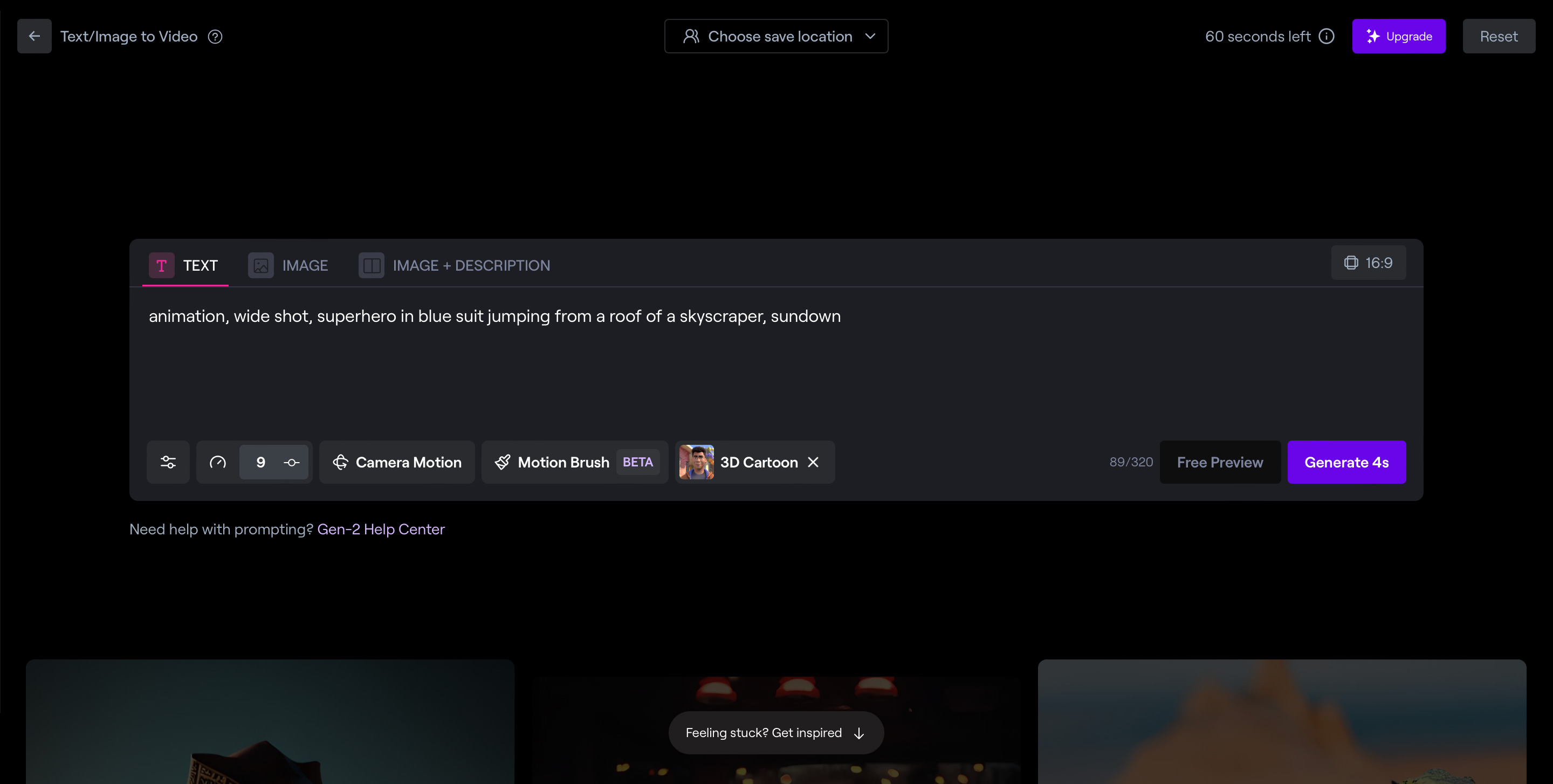
Редактор предлагает три режима работы:
- Text — генерация по текстовому запросу.
- Image — генерация по изображению. Загружаете картинку, которая используется как первый кадр видео, а анимацию полностью придумает нейросеть.
- Image + description — сочетание двух предыдущих методов. Загружаете картинку, с которой начнется анимация, и прописываете движения.
Рекомендую использовать первый и третий режим в зависимости от того, есть ли у вас картинка для первого кадра. Самодеятельность Runway обычно ни к чему хорошему не приводит — достойного результата добиться сложно.

Если хотите создать серию роликов в одном стиле, то закрепите сид . Тогда при каждой последующей генерации нейросеть будет обращаться к одним и тем же образам. То есть рыжая девушка в одном видео будет похожа на рыжую девушку в новом.
Если планируете создавать серию роликов в одном сеттинге, то рекомендую нажать галочку у пункта Fix seed between generations. Не забудьте убрать его, когда захотите сделать видео в другой серии.
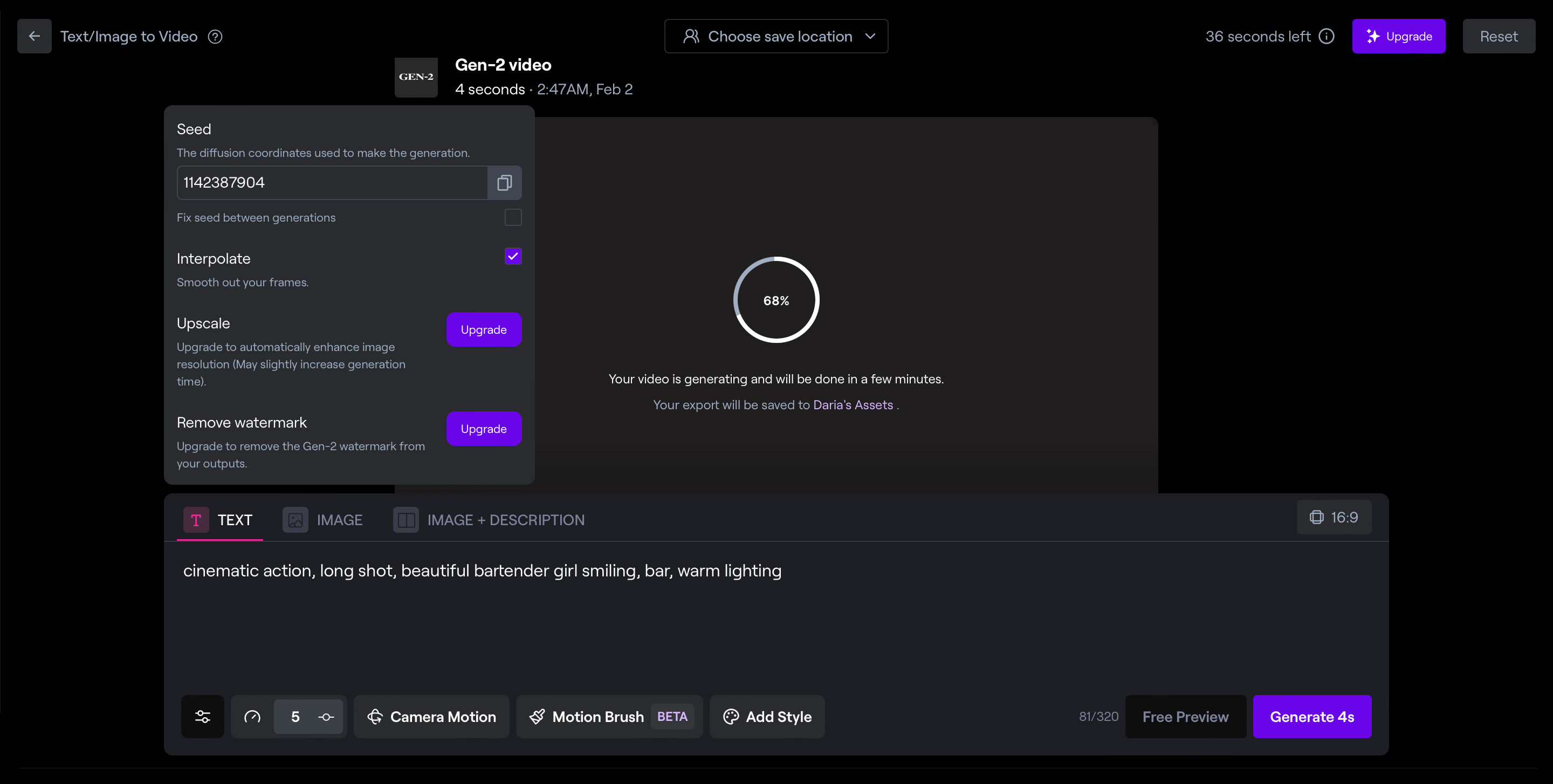
Вот что еще можно выбрать в настройках:
- Interpolate — параметр, который обеспечивает плавность перехода между кадрами. Без него видео получится более рваным и дерганным. По умолчанию он включен всегда, выключать не стоит;
- General Motion — амплитуда движений. Если хотите динамичный кадр, устанавливайте ближе к максимальному значению — 10;
- Camera Motion — по какой схеме и с каким наклоном будет двигаться камера. Доступно шесть вариантов: горизонтальное движение, вертикальное, смещение перспективы влево-вправо или вниз-вверх, круговое движение и приближение — отдаление;
- Motion Brush — мини-редактор, позволяющий по-разному анимировать объекты на картинке. Например, выделить разными цветами людей на фоне и собаку на среднем плане. Нейросеть поймет, что это разные элементы, и анимирует их по отдельности;
- Add Style — набор популярных стилей, которые можно добавить к промпту в виде тега: например, «3D-мультик», «аниме» или «импрессионизм». Доступно только при генерации по текстовому запросу.

Какие получаются результаты. Runway всегда генерирует сцены по четыре секунды. Другую продолжительность установить нельзя. На создание одного видео уходит около минуты.
Готовое видео нельзя редактировать, но можно увеличить продолжительность кнопкой «Extend 4s» — это добавит еще четыре секунды в ту же последовательность кадров. Одно видео можно расширять до тех пор, пока не закончатся кредиты.
Если нажать на кнопку «Generate 4s» снизу, то нейросеть перегенерирует видео по тому же запросу.



Все видео, сгенерированные в рамках одной сессии, отображаются в ленте слева. Это удобно, если нужно сделать несколько роликов и собрать из них последовательную историю. Неудачные кадры можно удалить, чтобы не мешались. Однако нет возможности поменять порядок.
Лучше всего у Runway получается мультяшная анимация и пейзажи. Реалистичные изображения людей выходят хуже — как и у большинства нейросетей для генерации видео. Хотя бы из-за того, что черты лица часто меняются в движении. Не говоря уж о лишних пальцах.
| Плюсы | Минусы |
|---|---|
| Хорошо работает с разными стилями | Нужно уметь писать промпты |
| Позволяет сохранять визуальный стиль между видео | Генерация людей часто пугает |
| Плюсы | |
| Хорошо работает с разными стилями | |
| Позволяет сохранять визуальный стиль между видео | |
| Минусы | |
| Нужно уметь писать промпты | |
| Генерация людей часто пугает |
Что умеет: генерирует видео по текстовому запросу или картинке
Поддерживает ли русский язык: интерфейс на английском, но промпты понимает на русском
Сколько бесплатных попыток: ежедневно по 25 видео продолжительностью 3 секунды
Что дает подписка: больше генераций и экспорт без водяного знака за 10 $ (900 ₽) в месяц, оплатить с российской карты нельзя
В каком формате экспортирует: MP4
Изначально сервис позволял создавать только простые гифки, но недавно запустил полноценный генератор видео Genmo Replay. Этот раздел находится на главной сайта.

Как пользоваться. Вместо кредитов генерации здесь используется fuel — «топливо». Каждому пользователю без подписки дают 100 пунктов в день, с подпиской — 1000.
Остаток «топлива» в редакторе и профиле не указывается, расход для генерации тоже. Но экспериментально я выяснила, что каждая попытка расходует четыре пункта «топлива». Ежедневно можно генерировать по 25 трехсекундных видео бесплатно. У меня на старте было 200 пунктов «топлива» вместо заявленных 100. Вероятно, бонусную сотню выдают за регистрацию.
Редактор устроен просто: поле ввода промпта и четыре кнопки — настройки видео, загрузка референсной картинки, настройки движения камеры и спецэффекты (FX).
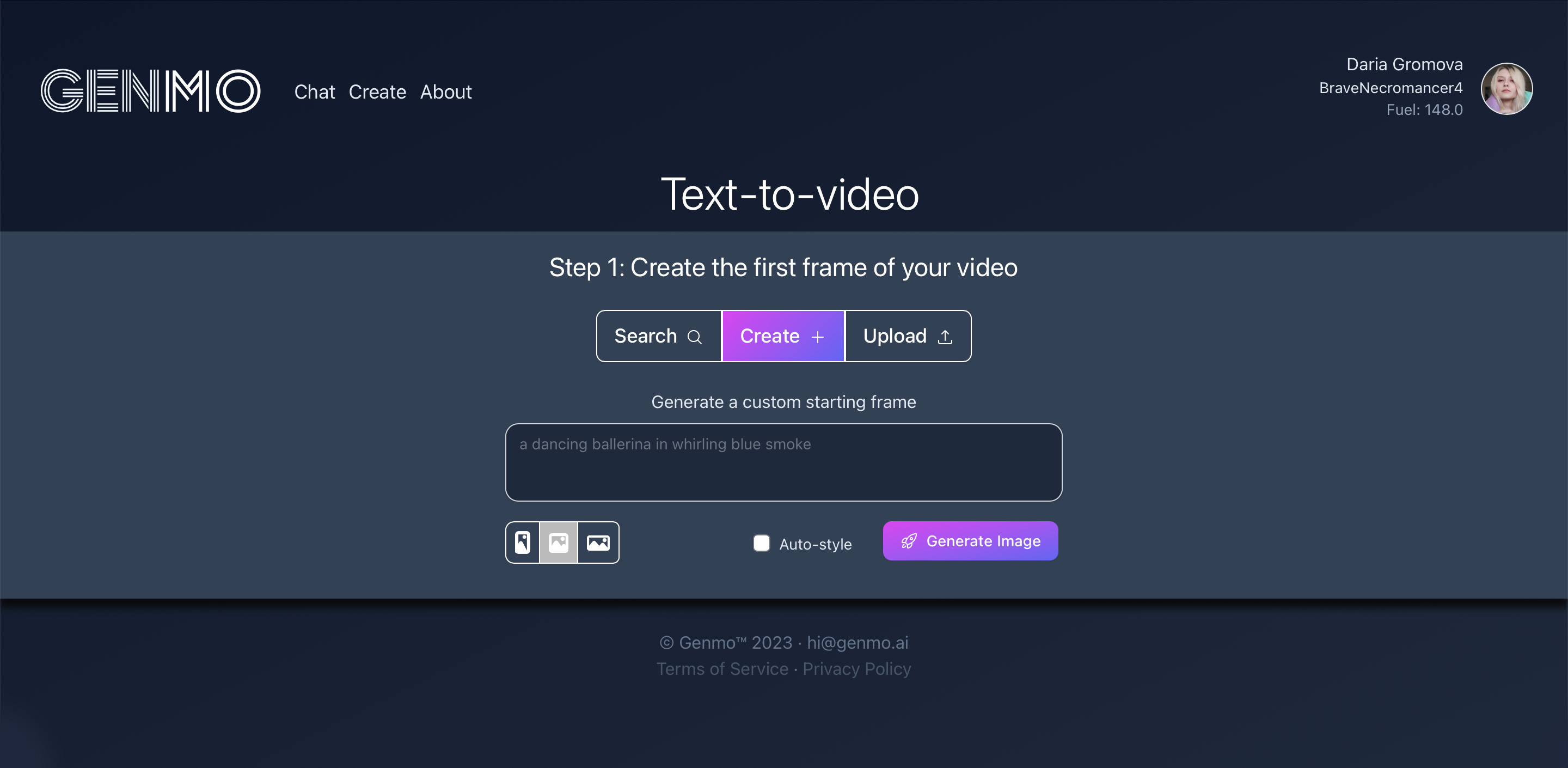
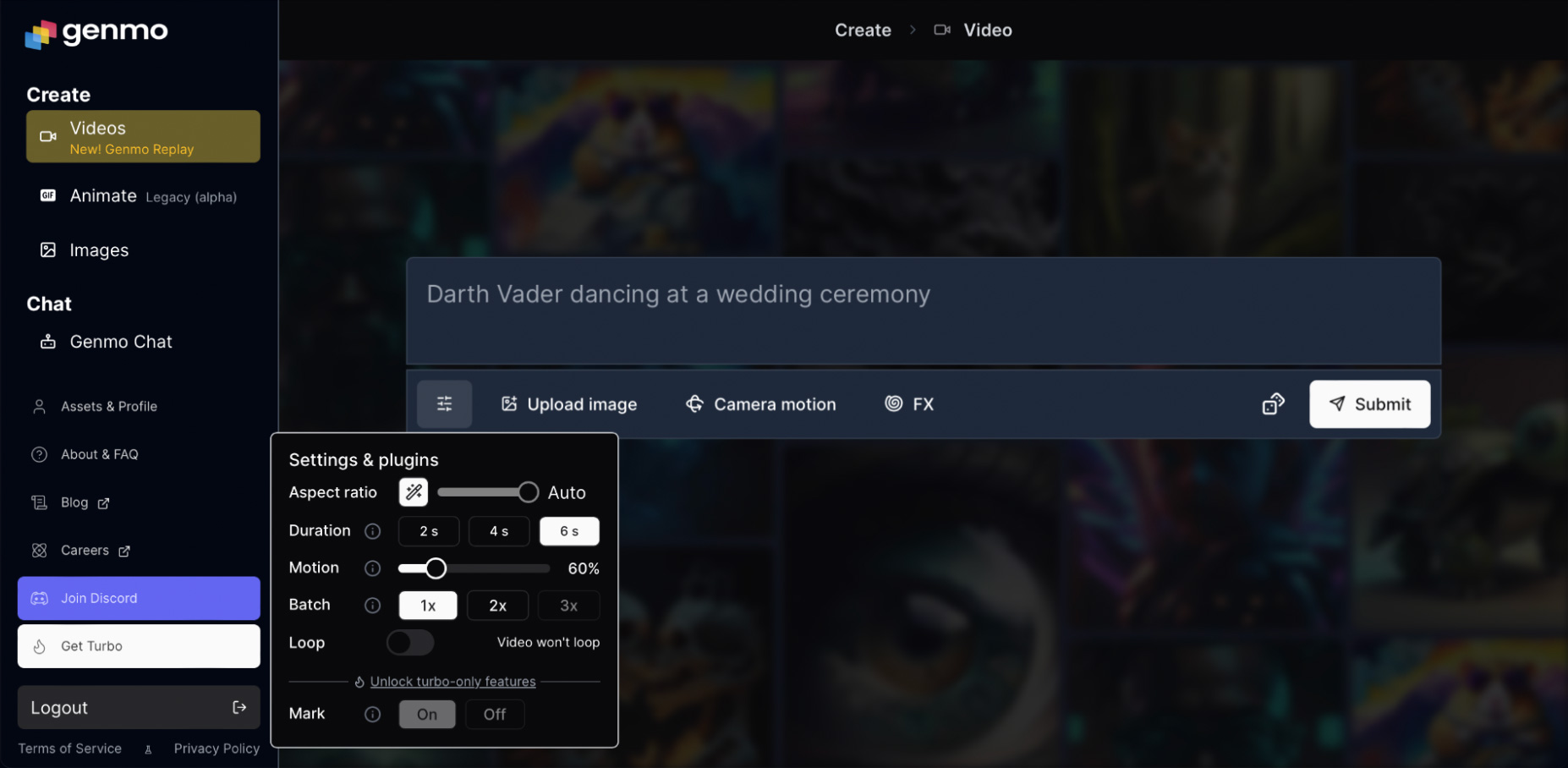
Настройки видео такие:
- Aspect ratio — соотношение сторон, можно выбрать значение от 9:16 до 16:9 или позволить выбрать нейросети по кнопке Auto;
- Duration — длительность видео. Обычно предлагается 2, 4 или 6 секунд, но иногда — 4, 8 или 12 секунд. От чего это зависит, мне неизвестно. Возможно, от нагрузки на сервер. Сначала генерируйте видео покороче, чтобы убедиться, что промпт устраивает;
- Motion — насколько активно двигается объект. Параметр можно установить от 1 до 100%. Выбирайте минимальное значение, если вам нужна нейтральная анимация. Выкручивайте к 70%, если нужно активное действие;
- Batch — сколько видео будет генерироваться по одному запросу. Без подписки — один или два ролика, с подпиской — три;
- Loop — зацикленное видео или нет. Если включить, последний кадр будет совпадать с первым для бесконечной анимации;
- Mark — отключает водяной знак Genmo. Доступно только с подпиской.
В разделе со спецэффектами находятся пресеты, которые сочетают движение камеры и эффект фона. Подходят для пейзажей и неодушевленных предметов, но странно смотрятся с людьми и животными.

Какие получаются результаты. Видео создается около минуты. В процессе ожидания демонстрируются отрисованные промежуточные кадры, между которыми сделают переходы.
Во время генерации видео Genmo предлагает подсказки для улучшения запроса. Если их использовать, то на это уйдет «топливо». Они работают только при вводе запроса на английском и то не при каждом запросе. Стили каждый раз случайные. К примеру, по промпту «смешное видео с кошкой, гиперреализм» он выдал такие предложения:
- sci-fi тематика — «гиперреалистичный кот, который ведет себя как человек»;
- хоррор-тематика — «гиперреалистичный кот, неподвижно сидящий в тревожной позе»;
- художественный стиль — «чересчур драматичный художник, который пишет портрет гиперреалистичного кота».
Сгенерированное видео нельзя редактировать или дорабатывать. Можно только скачать, попробовать еще раз или изменить промпт и настройки.





Нейросеть хорошо справляется с плавными анимациями с одним объектом. А вот визуализация нескольких активно движущихся людей или животных дается ей намного тяжелее.
Genmo подходит для не очень динамичных сцен. Сложные движения ей даются с трудом, но большое количество генераций это сглаживает. 25 попыток в день — очень щедро для бесплатных нейросетей. Можно не жалеть кредиты и переделывать то, что не понравилось.
| Плюсы | Минусы |
|---|---|
| Понимает промпты на русском | Плохо генерирует людей |
| Много бесплатных генераций, лимит обновляется каждый день | Остаток кредитов генерации прячется в неочевидном разделе |
| Не нужно расписывать сложные длинные промпты, общих фраз достаточно |
| Плюсы | |
| Понимает промпты на русском | |
| Много бесплатных генераций, лимит обновляется каждый день | |
| Не нужно расписывать сложные длинные промпты, общих фраз достаточно | |
| Минусы | |
| Плохо генерирует людей | |
| Остаток кредитов генерации прячется в неочевидном разделе | |
Что умеет: генерирует видео по текстовому запросу, картинке и видео
Поддерживает ли русский язык: интерфейс на английском, но промпты понимает на русском
Сколько бесплатных попыток: три ролика по три секунды в день
Что дает подписка: больше генераций и экспорт без водяного знака стоит 8 $ (723 ₽) в месяц, оплатить с российской карты нельзя
В каком формате экспортирует: MP4
Раньше сервис был известен как Pika Labs и был доступен только в Discord без лимитов. Именно поэтому в соцсетях расходились гифки из этого сервиса. Теперь у него появилась полноценная веб-версия, но с ограничениями по генерациям.

Как пользоваться. Окно ввода текстового запроса находится на главной странице. Снизу расположена кнопка для добавления изображения или ролика, видеонастройки и панель управления камерой.
Вот что можно настроить:
- Aspect ratio — соотношение сторон. Значения фиксированные: 16:9, 9:16, 1:1, 5:2, 4:5, 4:3;
- Frames per second — количество кадров в секунду. От 8 до 25;
- Camera control — устанавливает, по какой траектории будет двигаться камера и с какой скоростью;
- Strength of motion — насколько активно двигается объект. От 1 до 4;
- Negative Prompt — отрицательный запрос. То есть все, чего не должно быть на видео. Например, если хотите сгенерировать мужчину без шляпы, укажите no hat. Если нет особенных предпочтений, стоит вписать сюда слова ugly, bad, terrible. Эти ключевые слова предлагает сам редактор. Они позволяют отсеять некрасивые результаты;
- Consistency with the text отвечает за точность соответствия промпту — чем больше значение, тем выше соответствие;
- Seed — в поле можно ввести значение сида предыдущего сгенерированного ролика, чтобы сохранить визуальный стиль;
- Consistency with the text отвечает за точность соответствия промпту — чем больше значение, тем выше соответствие.
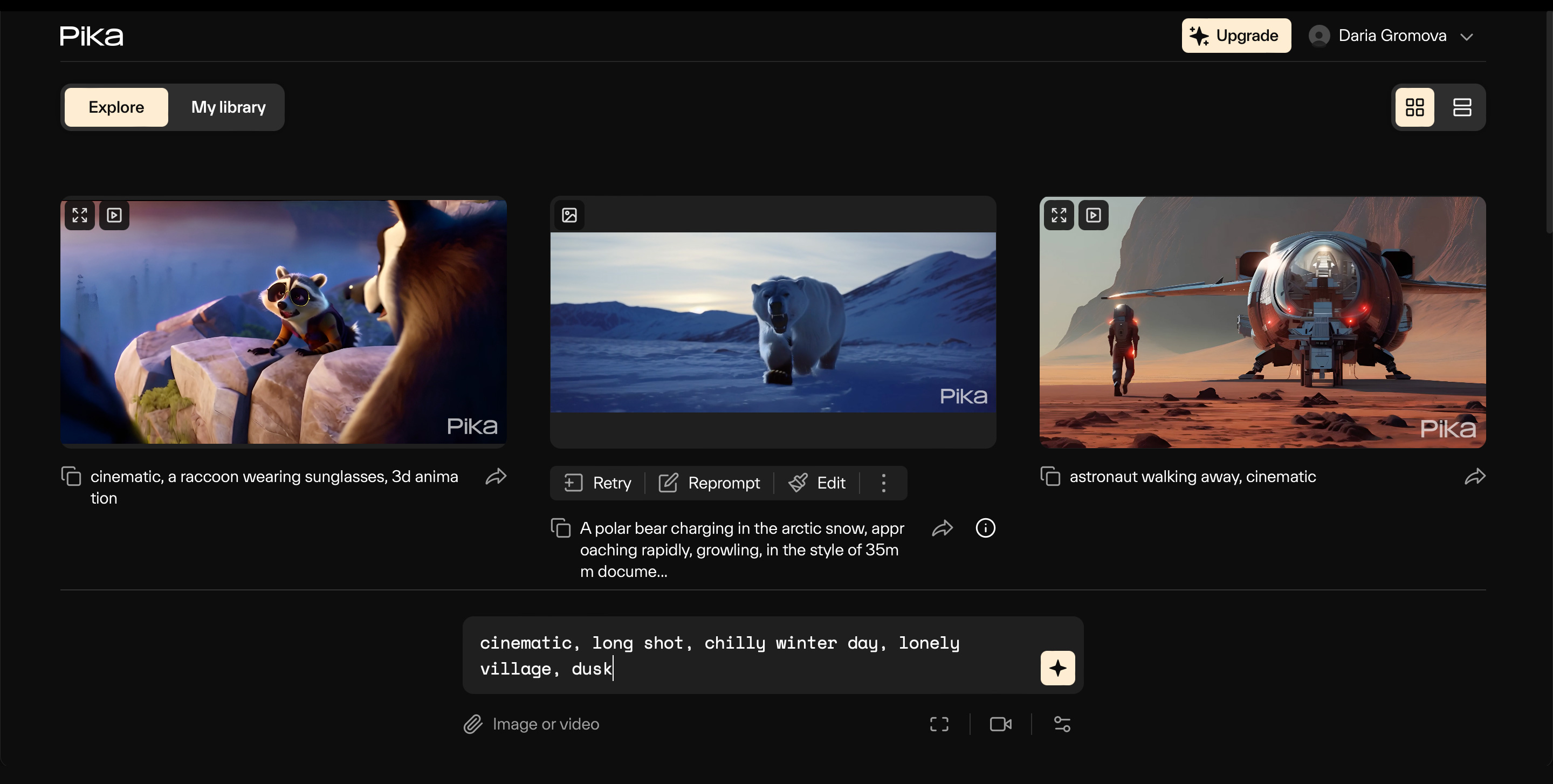
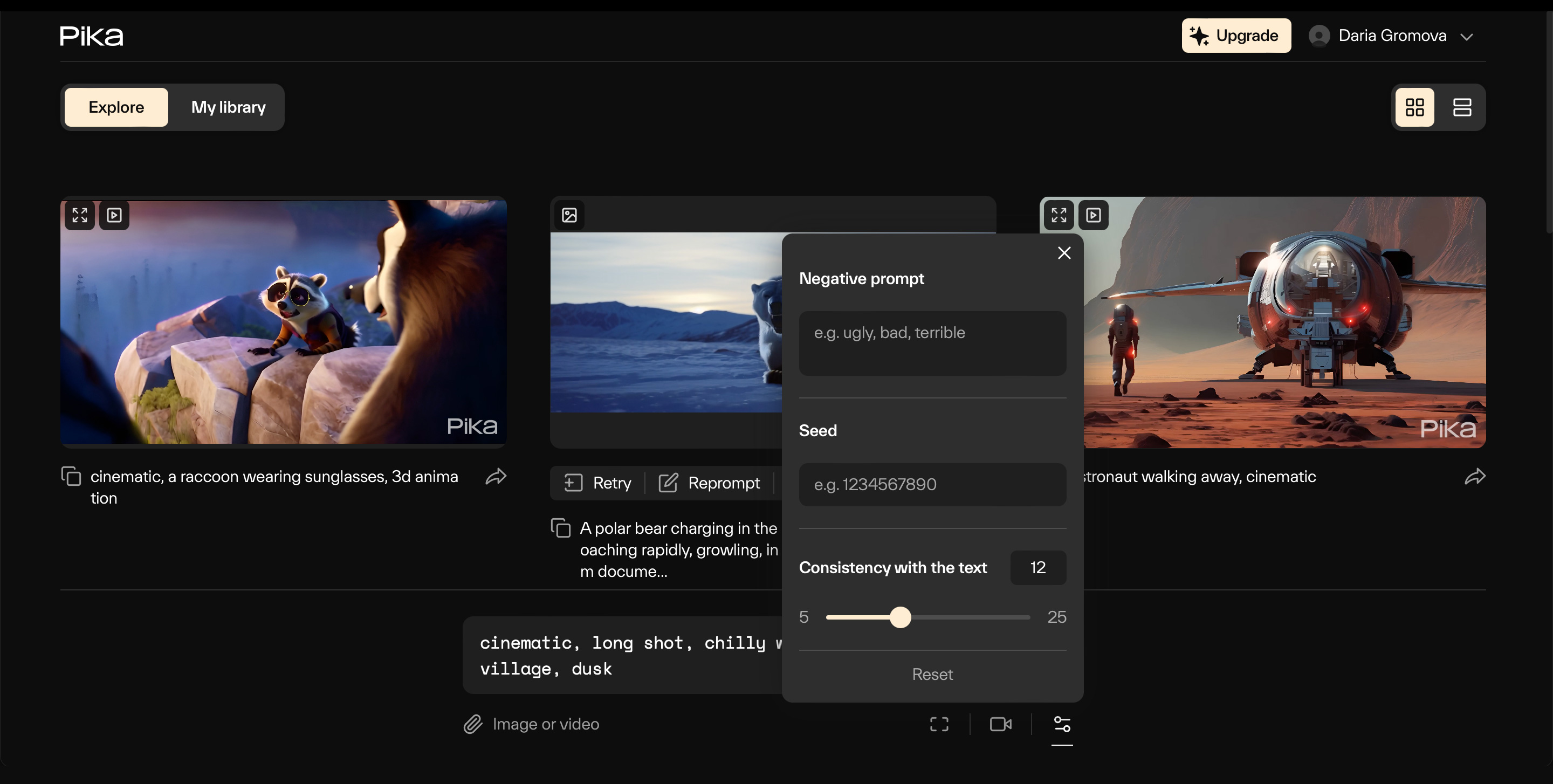
Нажмите на иконку со звездочкой для начала генерации. После этого откроется раздел My Library, где можно следить за прогрессом и посмотреть созданные ранее видео. Создание ролика займет около минуты.
В бесплатной версии всегда получается трехсекундный ролик вне зависимости от выбранного числа кадров в секунду. Без подписки в день можно сгенерировать только три ролика в сутки.
Под готовым видео будет две кнопки: Retry и Reprompt. Клик по первой запускает генерацию еще одного видео с тем же запросом, клик по второй позволяет сначала отредактировать промпт.
Результаты. Лучше всего Pika работает со стилизованным окружением, мультяшным стилем и с idle-анимациями. Так называют минимальные движения вроде дыхания и моргания.




Для анимирования людей и животных лучше загружать референсную картинку. Пока Pika генерирует с нуля хуже бесплатных нейросетей для создания картинок вроде Kandinsky. Получается жутковато.
Экспортируются видео только в MP4. В бесплатной версии на видео накладывается водяной знак с логотипом сервиса.
| Плюсы | Минусы |
|---|---|
| Генерирует атмосферные пейзажи | Мало бесплатных генераций |
| Можно добавлять отрицательные запросы и переносить визуальный стиль между видео | Плохо генерирует людей и животных без референса |
| Плюсы | |
| Генерирует атмосферные пейзажи | |
| Можно добавлять отрицательные запросы и переносить визуальный стиль между видео | |
| Минусы | |
| Мало бесплатных генераций | |
| Плохо генерирует людей и животных без референса |
Stable Video Diffusion
Что умеет: генерирует видео по картинке и текстовому запросу
Поддерживает ли русский язык: интерфейс на английском, промпты понимает на русском
Сколько бесплатных попыток: от 13 до 15 видео по 4 секунды в день
Что дает подписка: ее нет, но можно докупить 50 генераций за 10 $ (1000 ₽) или 300 генераций за 50 $ (5000 ₽), оплатить с российской карты нельзя
В каком формате экспортирует: MP4
Модель создали разработчики нейросети для генерации картинок Stable Diffusion — основного конкурента Midjourney и Dall-E 3. Главной фишкой называют понимание объема: алгоритм умеет додумывать, как выглядят предметы с других ракурсов. Stable Diffusion Video представили в конце ноября 2023 года. Доступно несколько версий.
Демо на Hugging Face — базовый редактор практически без настроек и с максимально простым интерфейсом, генерирует только 25 кадров за раз. Он не поддерживает текстовые запросы и анимирует только загруженные картинки.
Веб-приложение — полноценный веб-редактор с возможностью ввода текстового запроса, загрузки изображения и управления камерой. Чтобы получить к нему доступ, нужно встать в лист ожидания по кнопке Join App Waitlist. За две недели я так и не получила доступ.
Код — разработчики нейросети опубликовали в общем доступе веса и код, который можно установить на компьютер. Для этого нужны навыки запуска кода и достаточно мощный компьютер.
Веб-версией пользоваться проще и удобнее всего, поэтому сосредоточусь на этом варианте.

Как пользоваться. Генератор откроется сразу после регистрации. Видео можно создавать по картинке или по текстовому запросу, но механика работы немного отличается от описанных выше нейросетей.
Генерация расходует кредиты. Каждый аккаунт получает по 150 штук, раз в сутки они восполняются. Если в других нейросетях создание картинки как бы включено в пакет генерации по тексту, то здесь это полноценный шаг с отображением результата.
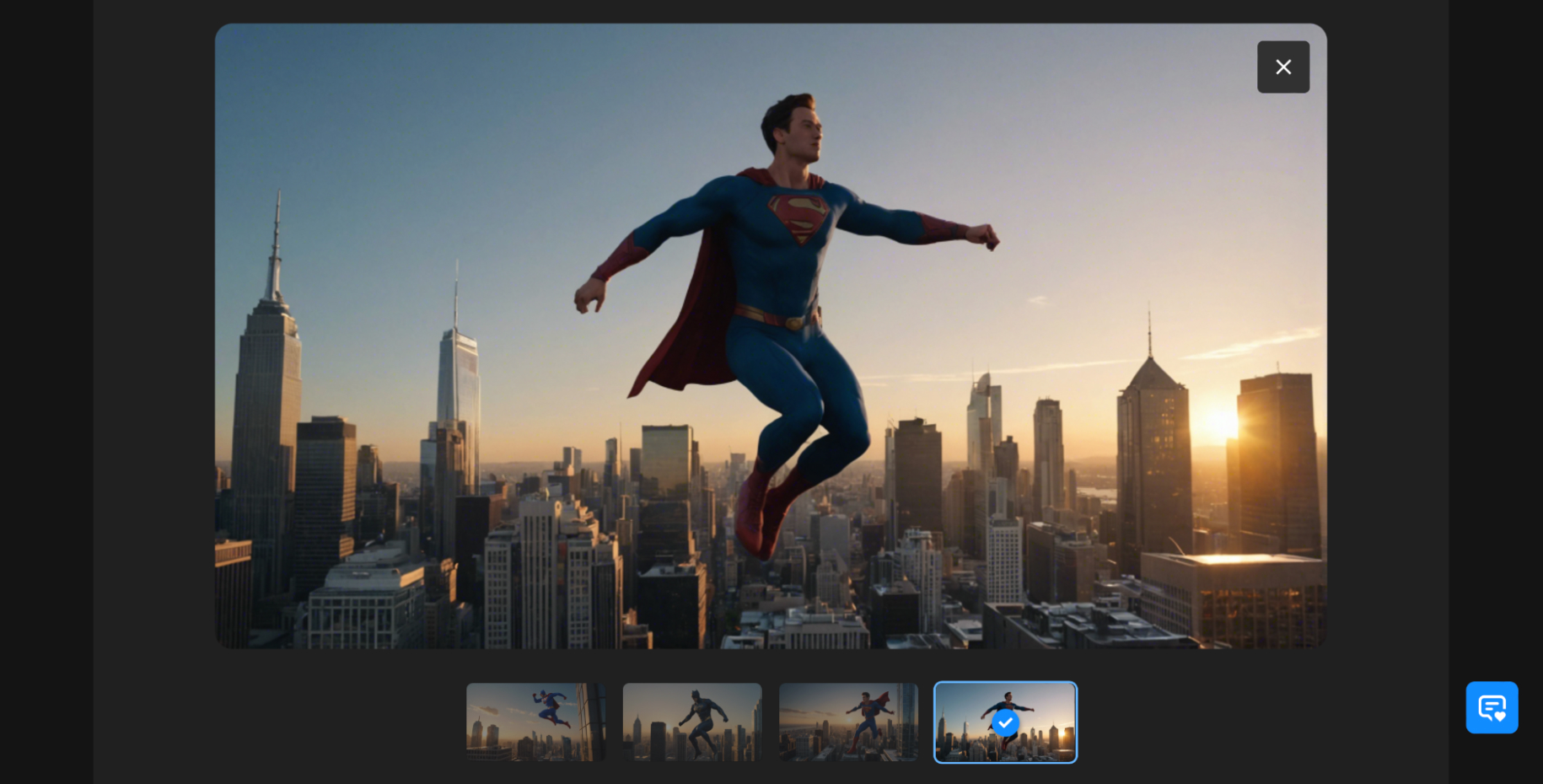
За 11 кредитов вы получаете от двух до четырех вариантов изображений. Из них можно выбрать любое и анимировать уже без дополнительной траты кредитов. Если картинки не понравились, можно потратить еще 11 кредитов на создание новой партии. Это удобно: пользователю не только дают выбор, но и позволяют сразу внести изменения, не дожидаясь создания анимации.



Перед генерацией можно настроить движение камеры — зафиксировать ее или имитировать тряску при съемке с рук, имитировать наклон вниз, облет по кругу, смещение вбок или приближение.
В разделе Advanced больше настроек:
- Seed — вставить сид от другого видео, чтобы сохранить визуальный стиль;
- Steps — количество проходов. Чем их больше, тем выше качество, но медленнее генерация. Можно выставить значение от 25 до 40;
- Motion Strength — амплитуда движения. Для спокойных сцен лучше выставлять меньше, для экшена — больше. Диапазон от 1 до 255.
Ввести текстовый промпт для анимации нельзя. После выбора нужных параметров остается нажать Proceed и ждать генерации. Она занимает минуту-две.
Если генерировать видео по существующей картинке, то доступны будут те же самые настройки, что на втором шаге генерации с промптом. Создание видео при этом будет стоить 10 кредитов, а не 11.
Результаты. На каждое видео уходило около двух минут с максимальным значением Steps. Ролик сохраняется в историю аккаунта, поэтому можно заниматься другими делами, а не ждать с открытой вкладкой.
Готовое видео нельзя изменить или дополнить, но под ним будут отображаться использованные промпт и настройки. Чтобы можно было сгенерировать еще раз, немного поменяв вводные.
Сгенерированный контент проходит автоматическую модерацию. В правилах отмечается, что проверка идет на наготу, неприемлемый и защищенный авторским правом контент. Не уточняется, что именно подпадает под неприемлемый контент, но нейросеть иногда норовит создавать его по самым простым и невинным запросам.
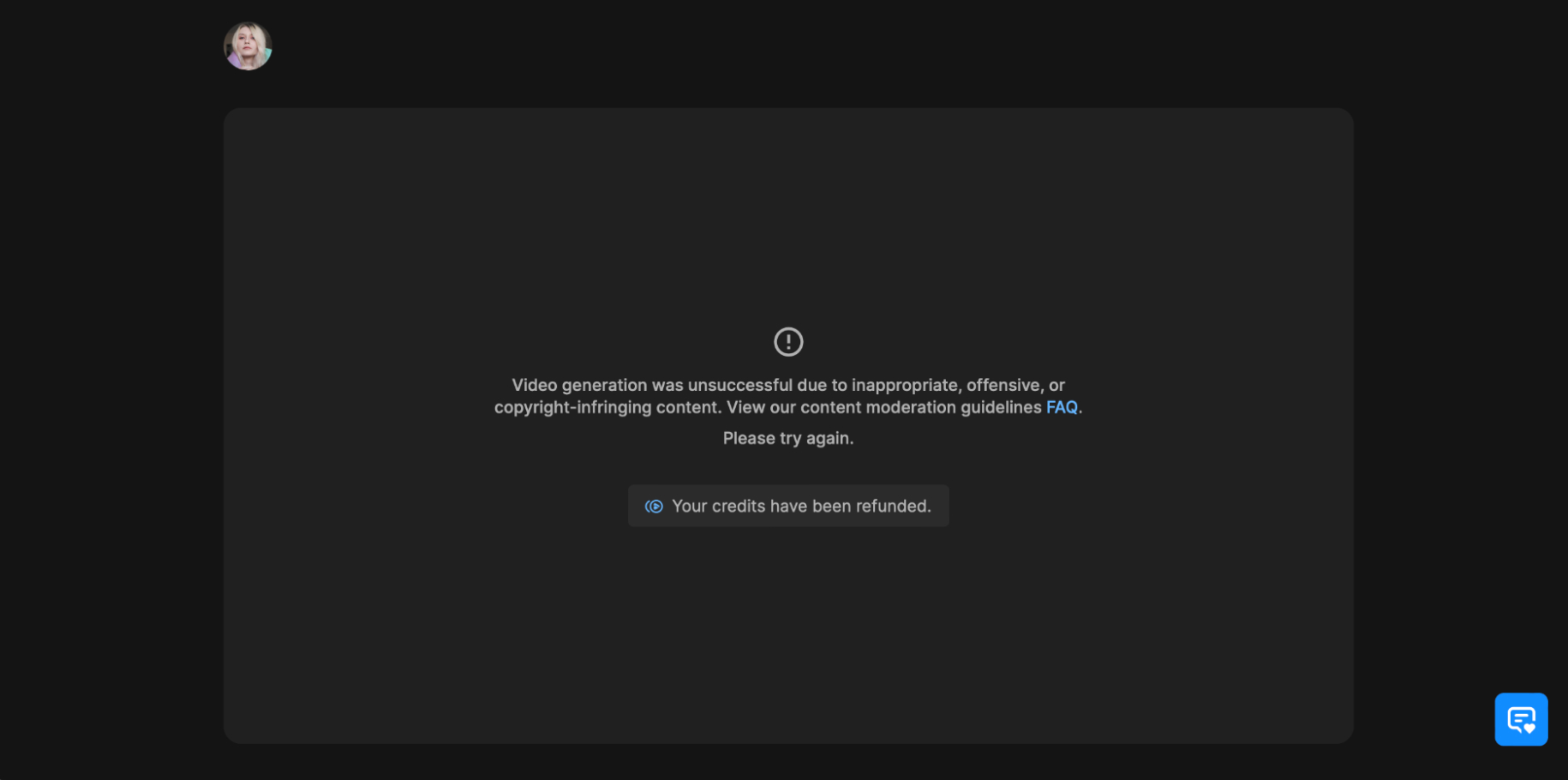
Если что-то найдут, то созданное видео не покажут, но кредиты вернут. При генерации по текстовому промпту возвращают только 10 кредитов вместо 11, если проблема возникла на этапе создания видео. На всякий случай понравившиеся картинки лучше сохранять.
По качеству генераций видно, что это еще только первая версия. Фишка с обучением на 3D-моделях отражается в том, что нейросеть хорошо отделяет объекты от фона, а вот с дорисовкой промежуточных кадров и изменением положений у нее пока туговато.

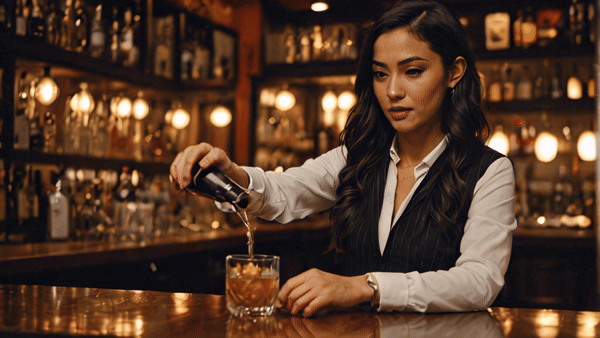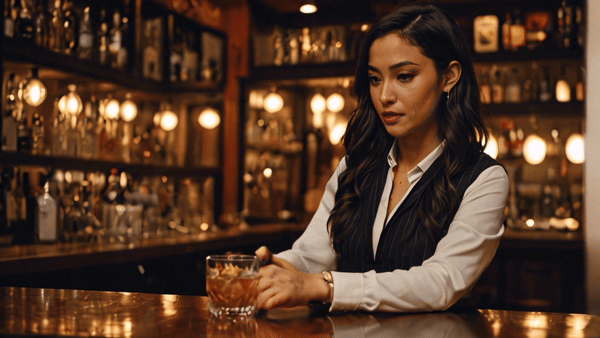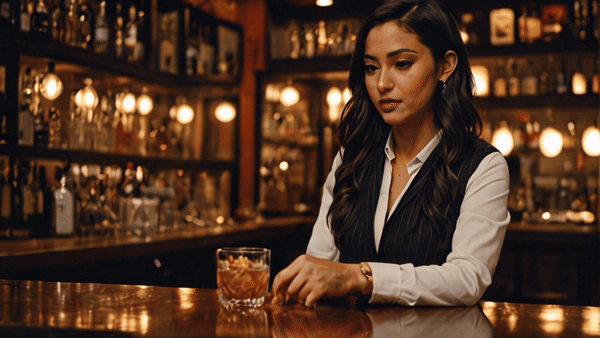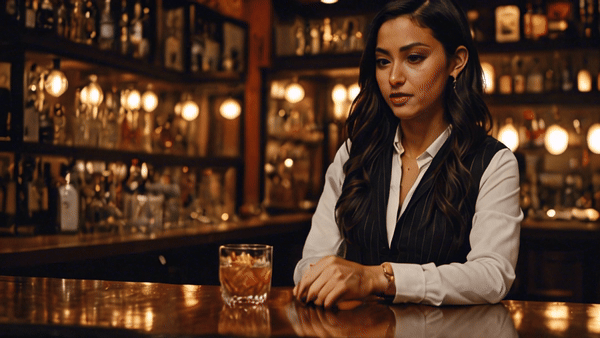


Нейросеть генерирует красивые картинки, но адекватной анимации людей или мультяшных героев от нее пока не добиться. Вменяемо выглядят видео, созданные с низким значением Motion Strength и без четких требований к движениям.
В целом проблемы Stable Video Diffusion такие же, как у прочих нейросетей в списке. Ей плохо удается показывать действия, а хорошо получается вращать камеру вокруг статичных объектов и делать idle-анимации.
| Плюсы | Минусы |
|---|---|
| Предлагает несколько вариантов картинок, а не выбирает основу сама | Нельзя загрузить картинку и добавить промпт |
| Обучена на 3D-моделях и хорошо отделяет объект от фона | Плохо дорисовывает объекты в движении |
| Много бесплатных попыток в день | Может жаловаться на неприемлемый контент по самым простым запросам |
| Плюсы | |
| Предлагает несколько вариантов картинок, а не выбирает основу сама | |
| Обучена на 3D-моделях и хорошо отделяет объект от фона | |
| Много бесплатных попыток в день | |
| Минусы | |
| Нельзя загрузить картинку и добавить промпт | |
| Плохо дорисовывает объекты в движении | |
| Может жаловаться на неприемлемый контент по самым простым запросам |
Мы постим кружочки, красивые карточки и новости о технологиях и поп-культуре в нашем телеграм-канале. Подписывайтесь, там классно: @t_technocult