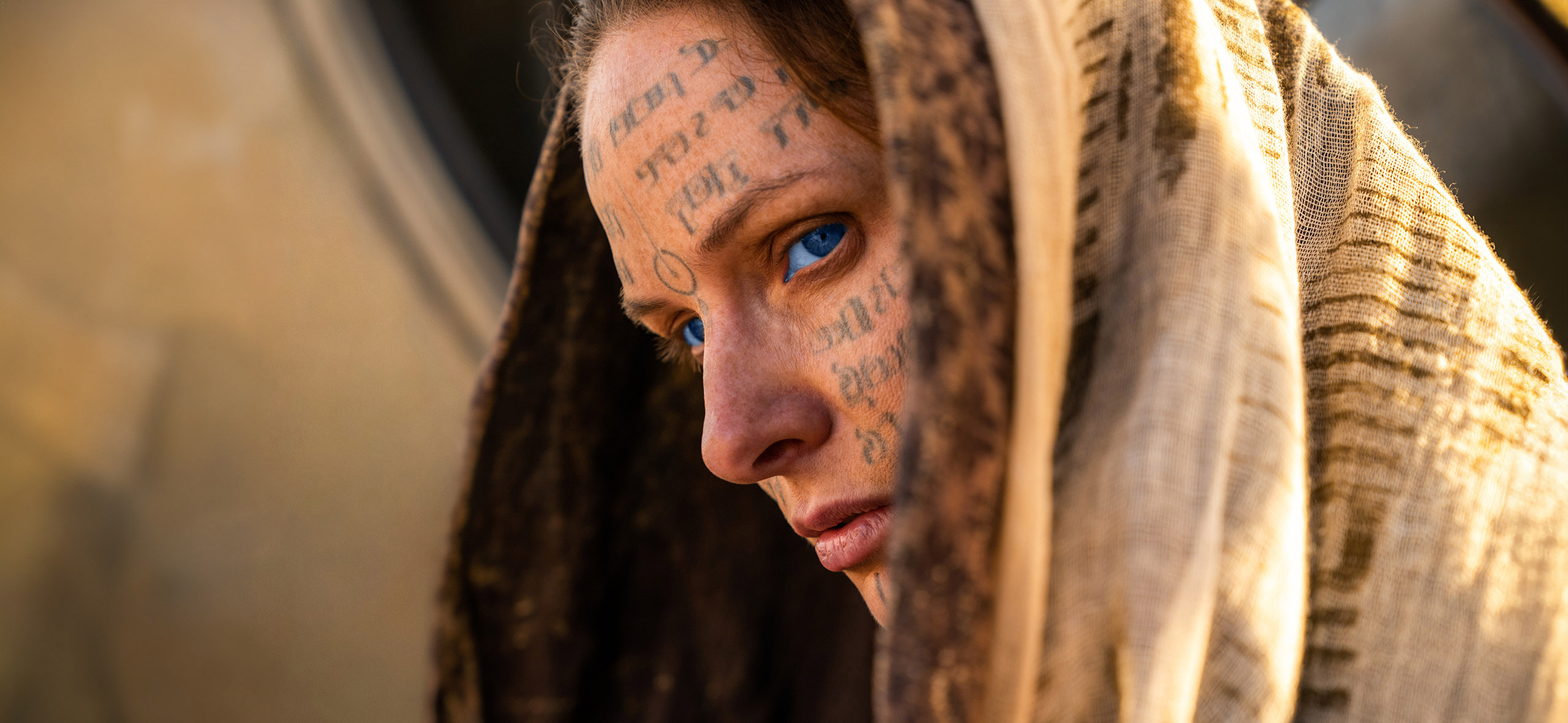Как пользоваться нейросетью Kandinsky 2.2


Kandinsky 2.2 — нейросеть от Сбера, которая генерирует картинки по текстовым запросам.
Главная особенность сервиса в том, что он работает с русским языком и генерирует приближенные к фотореализму картинки. Можно описать изображение, задать стилистику, уточнить детали. А еще нейросеть умеет генерировать короткие анимационные ролики. В отличие от многих аналогичных сервисов, Kandinsky 2.2 неплохо понимает русскоязычные запросы и учитывает их при генерации.
Рассказываем, почему стоит обратить внимание на нейросеть, как она справляется с задачами и как показывает себя на фоне главного конкурента.

Что собой представляет Kandinsky 2.2
Сервис Kandinsky 2.1 появился весной 2023 года. Тогда Сбер сильно улучшил свою модель и повысил уровень генераций. У нее неплохо получались арты, но иностранные проекты Midjourney и Stable Diffusion к тому моменту уже перешли от красивых рисунков к фотореализму. Как раз в ответ на это летом появилась версия Kandinsky 2.2, главной фишкой которой называют фотореализм. Подробнее об этом можно почитать в блоге компании на «Хабре».
Принцип работы нейросети не отличается от конкурентов: она рисует изображения в разных стилях на основе текстового запроса. Но разработчики «Кандинского» заявляют о поддержке более 100 языков, в том числе и русского, чем не могут похвастаться преимущественно англоязычные Midjourney или Stable Diffusion. Есть и исключения — нейросеть Dall-E 3 от Open AI тоже хорошо работает с русским языком.

У нейросети от Сбера есть шесть основных режимов работы:
- Генерация по тексту. Стандартная функция: необходимо написать текстовый запрос, а нейросеть нарисует по нему изображение.
- Смешивание изображений. Можно загрузить две картинки и посмотреть на микс от нейросети.
- Вариации изображения. Если добавить уже готовую картинку или фото, а затем задать определенную стилистику, можно получить новое изображение.
- Дорисовка. Обычно этот режим называют outpainting. Можно взять фото или картинку, а затем попросить нейросеть дополнить ее — дорисовать оставшиеся за кадром детали.
- Перенос стиля. Это аналог плагина ControlNet от Stable Diffusion. Функция позволяет переносить позу персонажа или очертания исходного изображения на новую сгенерированную картинку.
- Генерация видео. Нейросеть генерирует четырехсекундные гифки, которые можно склеить в небольшой ролик.
Где попробовать нейросеть Kandinsky 2.2
Есть несколько способов:
- На сайте fusionbrain.ai — это тестовый сайт команды «Кандинского». Там можно генерировать на основе текста и использовать режим дорисовки.
- В официальном телеграм-боте — там доступны четыре режима генерации; дорисовывать изображение нельзя. Зато если пользоваться ботом в мобильном приложении «Телеграма», можно создавать стикеры для мессенджера.
- На сайте Rudalle — так называлась самая первая версия нейросети Сбера для генерации картинок. Доступно только создание картинки по текстовому запросу.
- С помощью навыка «Включи художника» в голосовом помощнике «Салют» от Сбера.
- В боте во «Вконтакте». Только создает картинки по тексту.
- В телеграм-боте для генерации видео. Пока доступен только по предварительным заявкам и не всем пользователям.
Телеграм-бот — один из самых удобных способов. Он бесплатный, быстро генерирует и поддерживает основные режимы. В «Телеграме» есть боты других нейросетей, но им нельзя доверять: часто их запускают мошенники. Тут же все официально.
В любом из интерфейсов нейросеть может не сработать. Время от времени появляются ошибки и на сайтах, и в телеграм-боте. Сбер объясняет это большой нагрузкой на сервис.

Как генерировать картинки в Kandinsky 2.2
Я пользовался двумя способами: телеграм-ботом и платформой fusionbrain.ai. Второе — полноценный сайт для генерации картинок. Есть область, вместо которой появится изображение, текстовое поле для запроса, а также выбор основных стилей.
Квадратом выделена как раз область генерации. Ее размеры можно изменять. Это не особенно полезно при стандартной генерации по тексту, может пригодиться в других режимах.


Сейчас доступно около двадцати стилей, список и количество время от времени меняются. Набор обычен для аналогичных сервисов: киберпанк, аниме, карандашный рисунок, традиционная живопись. Из нестандартных отдельным пунктом значится хохлома. Иногда со списком стилей экспериментируют, например добавляют «Советские мультфильмы» или «Новый год». Это не что-то уникальное: с самыми известными стилями русских народных промыслов и художников знакомы и англоязычные приложения.
По большей части стили работают хорошо, хотя почти всегда нужно несколько попыток. В текстовом запросе можно добавлять стилистику самостоятельно, если ее нет в списке. В этом случае нужно поставить галочку у пункта «Без стиля».
Можно написать не только что вы хотите видеть на картинке — запрос в поле «Промпт», но и то, чего на ней быть не должно — на вкладке «Негативный промпт». Эта функция есть и в телеграм-боте: надо выбрать в меню «Изменить негативный промпт» или ввести команду /negative_prompt.
В запросах можно использовать эмодзи, но не все нейросеть поймет и воспримет. Например, на момент написания текста «Кандинский» узнает салатовый цвет 💚, череп 💀, единорога 🦄 или цветочек 🌷, но по запросу с единорогом и цветочком 🦄🌷 рисует хамелеона в букете. А подарок 🎁, туалетную бумагу 🧻 или клоуна 🤡 не воспринимает. Понять закономерность не удалось.
Картинки генерируются в пяти разрешениях 1:1 (1024 × 1024 точек), 2:3 (680 × 1024), 3:2 (1024 × 680), 9:16 (576 × 1024), 16:9 (1024 × 576).







В телеграм-боте стандартно предлагается на выбор четыре стиля: artstation , 4K, anime и «без стиля». Но можно прописать его в текст запроса, хотя понимает в этом случае нейросеть хуже. Бот во «Вконтакте» и вовсе не предлагает выбрать стиль, только задать текстовое описание и выбрать соотношение сторон из трех вариантов: 1:1, 2:3, 3:2.



Редактирование уже сгенерированного изображения — интересная функция. На готовой картинке можно воспользоваться инструментом «ластик» и закрасить им часть, которую нужно поменять. А затем снова нажать кнопку «Создать».
Так я несколько раз менял человека в красном пальто на улице киберпанковой Москвы. Нейросеть очень четко работала по контуру и не искажала остальное изображение. Это действительно полезный инструмент. Он доступен только если пользуетесь «Кандинским» на сайте fusionbrain.ai.






Дорисовка — тоже инструмент, который есть далеко не во всех сервисах. Работает это так: вы генерируете или загружаете картинку, а затем уменьшаете ее так, чтобы поле генерации было больше изображения. Потом дописываете текстовый запрос или выбираете стиль, после чего нейросеть будто дорисовывает картинку. Такая возможность есть только на fusionbrain.ai, в ботах ее нет.
Я попробовал режим на примере Шрека — изобразил его в киберпанк-стиле. Сервис неплохо дорисовал тело зеленого огра, сохранив его особенности и детали одежды. А вот лес c оригинального кадра стал проблемой, в итоге он сильно выделяется на фоне типичного киберпанк-города. Хотя нейросеть попыталась обыграть деревья, превратив их в странную зеленую сферу.


Перенос стиля позволяет задавать дополнительные входные условия — позу персонажа и очертания исходной картинки. Можно взять фото человека, прогнать его через нейросеть и заменить только внешность с сохранением остальной композиции. Функция доступна только в телеграм-боте.
Я попробовал смешать Шрека с Райаном Гослингом из «Бегущего по лезвию». Получилось неплохо: Kandinsky 2.2 скопировал стилистику и выражение лица Гослинга, но сохранил узнаваемые черты Шрека. Есть и недостаток: никак нельзя повлиять на результат генерации — к примеру, установить процент заимствования. Вы просто загружаете две картинки и ждете результата.



Смешивание картинок работает похожим образом, но только нейросеть не принимает во внимание позу персонажа и положение объектов. Она просто смешивает элементы двух картинок случайным образом, поэтому могут получаться непредсказуемые результаты. Работает тоже только в телеграм-боте.
Из смешивания Шрека с Райаном Гослингом получился герой боевиков 90-х, не похожий ни на огра, ни на голливудского актера. Нейросеть заимствовала стилистику у обеих картинок: лес от Шрека и освещение от «Бегущего по лезвию».

Управлять результатами смешивания картинок можно в «Профессиональном режиме», если выбрать в меню телеграм-бота соответствующий пункт или ввести команду /profmode. Тогда бот предложит выбрать влияние каждой из исходных картинок на результат. По умолчанию — 50:50, еще доступны варианты 30:70 и 70:30.
Стикеры для «Телеграма» можно создать прямо в боте. Kandinsky 2.2 сгенерирует по запросу упрощенный стилизованный рисунок с белой обводкой. Можно сразу создать новый стикерпак, а можно добавить сгенерированную картинку в уже существующий.
Сложные запросы Kandinsky 2.2 не воспринимает: у него не получилось сделать капибару со стаканчиком кофе или капибару за компьютером. А вот капибара в одеяле получилась более-менее, хотя часть тела пропала.

У стикерпаков от бота Kandinsky 2.2 есть недостаток: доступ к управлению ими получаете не только вы, но и бот. Вот чем это неудобно. Когда вы сгенерировали стикер, бот спросит, создать для него новый стикерпак или добавить в какой-то из уже существующих — но тоже созданных только этим ботом. Можно вручную ввести название чужого пака и добавить туда свой стикер.

Как Kandinsky 2.2 генерирует фотореализм
При использовании Kandinsky 2.2 я неоднократно думал, что стилистически результаты напоминают мне популярную нейросеть Midjourney. Причем пятое поколение, которое сделало ставку на фотореализм — v5. Поэтому я решил напрямую сравнить сервисы. Я составлял запросы для «Кандинского» на русском языке, а затем переводил их на английский и использовал в Midjourney.
Вывод: Midjourney, конечно, генерирует картинки более высокого качества и лучше работает с деталями. У Kandinsky 2.2 цвета более яркие и насыщенные, как будто контрастность выкрутили на максимум. В остальном стилистически он рисует похожие изображения.

В чем плюс — нейросеть полностью бесплатная, в отличие от Midjourney. Раньше у иностранного сервиса хотя бы была пробная версия. Но уже несколько месяцев эта возможность закрыта для новых пользователей. Оплатить же Midjourney из России проблематично.
Вот несколько примеров от двух нейросетей. Слева — Kandinsky, справа — Midjourney v5.










Как генерировать видео в Kandinsky 2.2
В октябре 2023 года Сбер объявил, что теперь «Кандинский» позволяет создавать короткие анимационные ролики. Их нельзя назвать полноценными видео, скорее четырехсекундными гифками, которые можно склеить между собой. До реализма качество генераций недотягивает.
Но доступ к телеграм-боту с этой функцией есть только у некоторых активных пользователей, остальным возможность создавать видео обещали дать до конца 2023 года. Пока же можно подать заявку в боте и посмотреть примеры на сайте проекта. Заявки рассматривают с разной скоростью: одному редактору Т—Ж дали доступ за неделю, а другому не ответили за две.
Вот как генерировать анимацию в боте:
- Сформулировать текстовый запрос как и при генерации картинки. Можно задать сюжет, стиль, детали.
- Бот предложит выбрать один из 16 эффектов анимации, то есть задать движение камеры: повернуть объект, обойти его, отдалить или приблизить. Примеры можно посмотреть прямо в боте по команде /examples. Обратите внимание: если камера движется вправо, объект на видео как будто движется влево. Это видно на примерах.
- Ввести еще два описания и выбрать для них эффекты. Это то, что будет происходить в видео дальше, как бы в следующих сценах. Но это не обязательно, можно генерировать одну сцену.
- Выбрать разрешение и завершить сценарий. Доступные варианты — квадратное видео 640 × 640 пикселей, вертикальное 448 × 832 или горизонтальное 832 × 448.

По одному запросу сгенерируется одно видео длиной четыре секунды. Если сцен в запросе несколько, то, соответственно, получится восемь или 12 секунд в одном ролике. Чтобы сделать видео подлиннее, можно склеить несколько генераций в стороннем сервисе.
Чтобы анимировать сцену, нейросеть рисует много-много картинок, в каждой следующей меняя положение элементов. А чтобы это смотрелось как единое движение, используется тот же перенос стиля — то есть каждый следующий кадр создается на основе предыдущего. Но такой контроль пока не полностью избавляет результаты от артефактов.

Вот несколько советов, которые помогут получать лучшие результаты при генерации видео в «Кандинском». Пока они касаются в основном того, как сгладить несовершенство ранних версий модели.
Меньше мелких деталей — меньше мерцание. Из-за того, что каждый кадр прорисовывается заново и чуть-чуть иначе, анимация заметно мерцает. Когда шевелятся листья на дереве или распущенные волосы, это воспринимается нормально. Когда оживают татуировки или начинают извиваться украшения — не всегда. Поэтому при генерации видео упоминания мелких деталей в запросе пока лучше избегать.
Стиль лучше прописывать, а формулировки повторять. Особенно это важно, когда в запросе две или три сцены. Стиль изображения нужно указать для каждой. А описание центрального объекта копировать слово в слово — так больше шансов, что он не изменится до неузнаваемости за 12 секунд.


Учитывайте движение. Еще одна особенность видео в Kandinsky 2.2 — морфинг. Это когда при движении объект как бы перетекает из одной формы в другую. Это стоит учесть в сценарии и продумать, как сделать переход между сценами плавным. Или же использовать как художественный прием: бумажный самолетик превращается в настоящий, волосы становятся волнами.


Лучше сначала проверить промпт на картинках. Сгенерируйте изображения, поправьте запрос, а потом уже делайте по нему анимацию — так получится гораздо быстрее. Убедитесь, что Kandinsky 2.2 генерирует более-менее похожие картинки по этому запросу: в видео они будут перерисовываться много раз.
Соотношение сторон зависит от сюжета. Если центральный объект вашей анимации продолговатый — выбирайте горизонтальный или вертикальный кадр. А вот апельсин, например, лучше анимировать в квадратном кадре. Так при движении камеры объект будет смотреться естественнее.

Что в итоге
- Kandinsky 2.2 — бесплатная нейросеть, которая генерирует картинки и видео по текстовым запросам. Возможность создавать анимацию пока доступна не всем.
- В отличие от некоторых популярных нейросетей, Kandinsky хорошо понимает запросы на русском языке.
- В Kandinsky есть много режимов генерации, которыми легко воспользоваться: смешивание картинок, перенос стиля, дорисовка.
- Телеграм-бот генерирует картинки и позволяет сделать из них стикерпак.
- В версии 2.2 сделали упор на фотореализм, но по качеству нейросеть все еще уступает Midjourney.
- Kandinsky 2.2 умеет генерировать видео — на каждый кадр по одной статичной картинке. Пока это только короткие анимационные гифки, которые можно склеивать между собой. До реализма они недотягивают.
- Чтобы добиться приемлемого результата с генерацией видео, придется учитывать множество нюансов: повороты камеры, мерцание и морфинг.
Генерировали картинки в нейросетях? Поделитесь своими результатами и расскажите, какой запрос использовали