Как работает ControlNet: сервис для контролируемой генерации изображений


В феврале для нейросети Stable Diffusion вышло расширение ControlNet, которое может генерировать изображения по готовой картинке, наброску или позе.
С плагином результаты получаются намного качественнее. Теперь можно детально задать нейросети референс и влиять на процесс генерации. ControlNet решает даже давнюю проблему с рисованием рук. Мы протестировали плагин и рассказываем, как он работает, что в нем можно сгенерировать и где попробовать.
Что такое Stable Diffusion
Stable Diffusion — самая продвинутая нейросеть для генерации изображений с открытым исходным кодом. Она полностью бесплатна. Но для запуска нейросети нужен мощный компьютер и навыки программирования.
Зато у нейросети нет ограничений: она может качественно генерировать изображения на основе текстового запроса, дорисовывать наброски и переделывать картинки-референсы. Еще Stable Diffusion можно обучить на собственном датасете и создавать похожие по стилю, но уникальные изображения.
Почему ControlNet делает шаг вперед в генерации картинок
В чем революционность. Популярная нейросеть Stable Diffusion от компании Stability.AI уже генерирует качественные изображения. Однако пользователь не может контролировать результат генерации в полной мере. На нейросеть можно влиять текстовыми запросами и даже картинками-референсами, но все равно алгоритм много что додумывает сам.
Все меняет технология ControlNet, которую разработали исследователи из Стэнфордского университета. По сути это плагин Stable Diffusion, решающий проблему пространственной согласованности.

О чем речь. Раньше при генерации изображения на основе картинки-референса нельзя было указать нейросети, какие части менять, а какие оставить. А с помощью ControlNet можно задавать дополнительные входные условия — позу персонажа, очертания исходной картинки. Например, можно взять фото человека, прогнать его через нейросеть и заменить только его внешность с сохранением остальной композиции.
Для генерации с ControlNet всегда нужна картинка-референс — она выступает как трафарет. Плагин генерирует на основе оригинала наброски разных форматов, а потом использует их как базу для дальнейшей генерации. Это решает сразу несколько известных проблем нейросетей с генерацией групп людей, текста, рук, глаз и других мелких деталей. Раньше Stable Diffusion генерировал пальцы на основе «шума» из миллионов картинок разных пальцев, это зачастую давало странные результаты. Теперь она имеет четкий трафарет и может повторить контур руки.



Что может ControlNet и из чего она состоит
В ControlNet входят семь разных моделей. Изначально они применялись не в комплексе, а только по отдельности. Недавно появилась возможность использовать несколько моделей разом — функция называется Multi-ControlNet.
Перед генерацией нужно подобрать ту модель, которая лучше всего подходит для задачи, а затем загрузить в нее изображение. Модели могут обнаруживать края картинок, анализировать информацию о глубине, обрабатывать эскизы или повторять человеческие позы.
Вот какой есть выбор в ControlNet и как работает каждая модель.
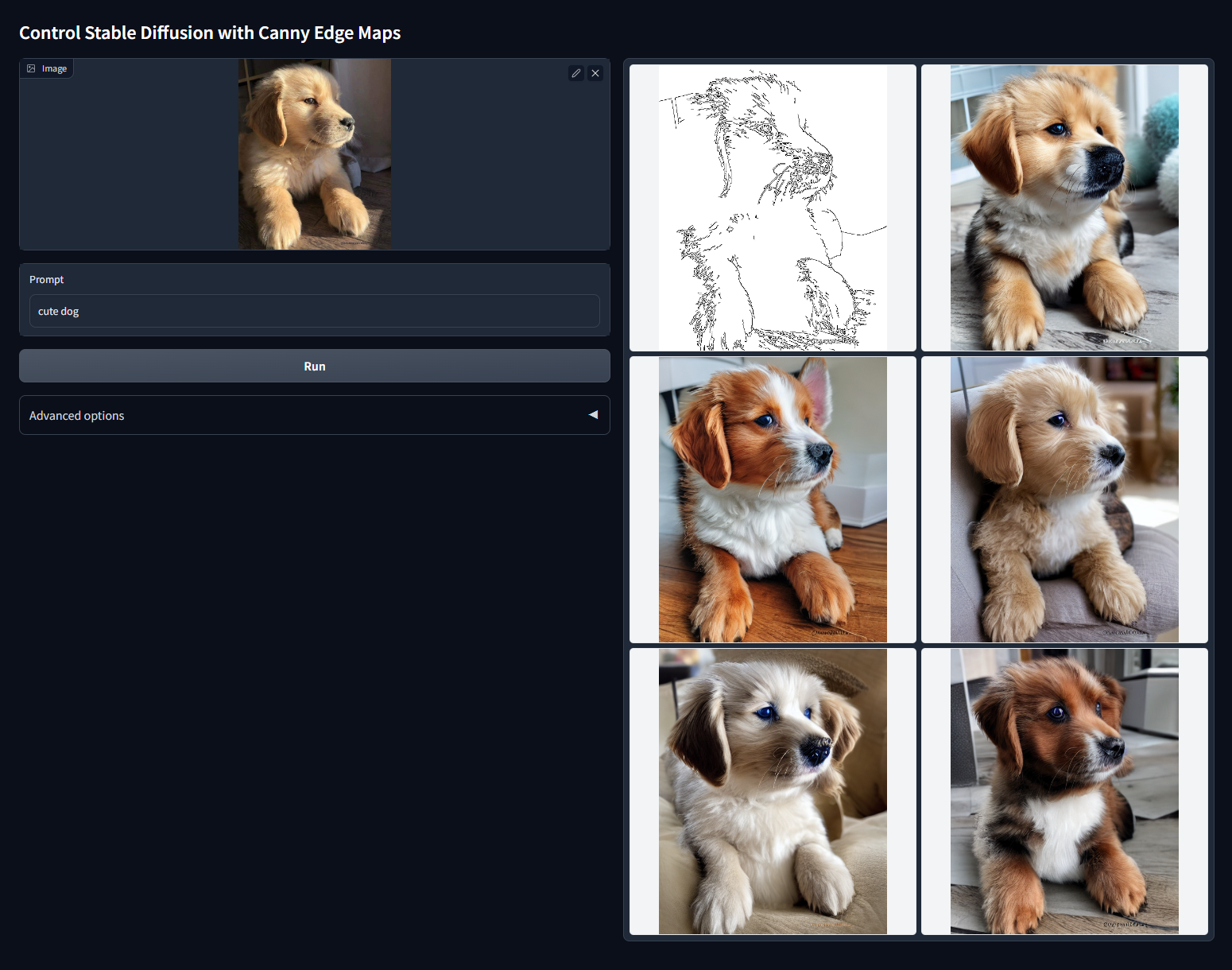
Модель Canny. После загрузки изображения-референса нейросеть рисует тонкой линией ее набросок. Так она довольно четко выделяет очертания объекта, сохраняя многие мелкие элементы.

При генерации ControlNet переносит этот набросок в новую картинку, а уже с помощью текстового запроса можно задавать параметры для нового изображения. Например, Canny позволяет заимствовать у картинки композицию и стилистику, но менять детали — скажем, лицо персонажа или цвета на картинке.
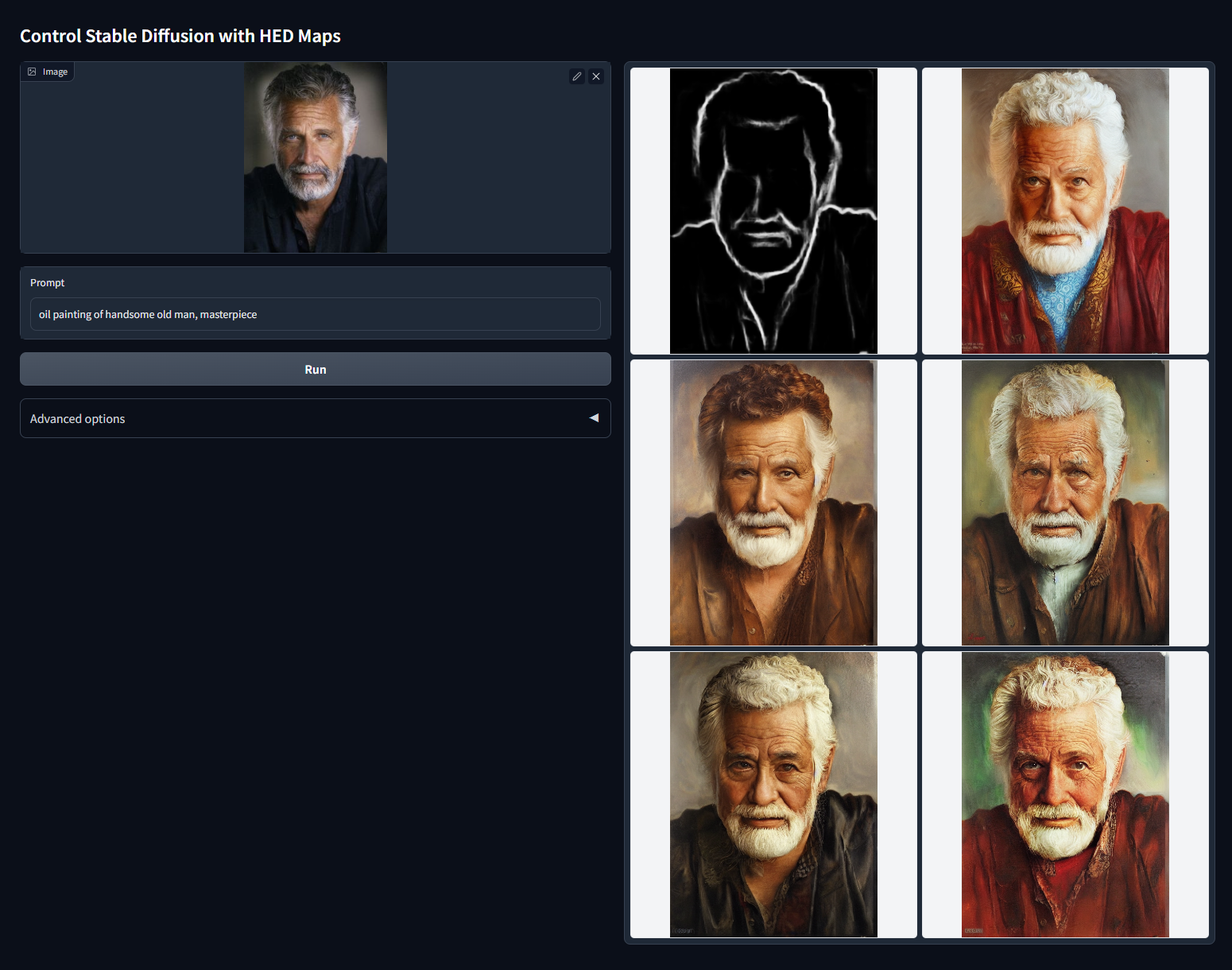
Модель HED, Holistically-Nested Edge Detection. Нейросеть при загрузке картинки размыто и неаккуратно очерчивает объекты на ней так, как это сделал бы человек.
Полезна для перекраски или изменения стилистики.
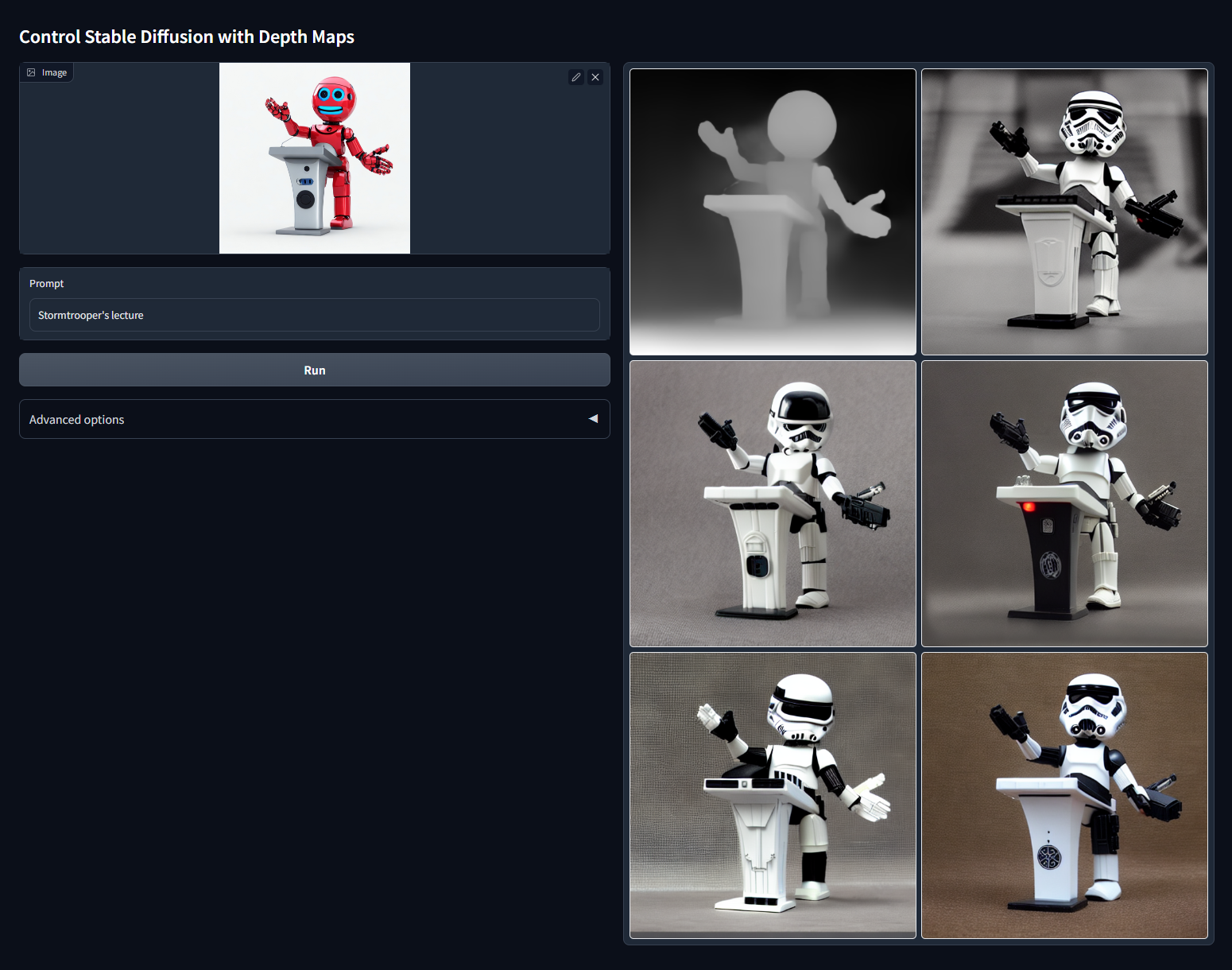
Модель Depth Map. При загрузке создает набросок картинки с картой глубины — показывает, какие объекты располагаются ближе, а какие дальше.
Модель удобна для случаев, когда нужно заимствовать с изображения композиционную глубину.
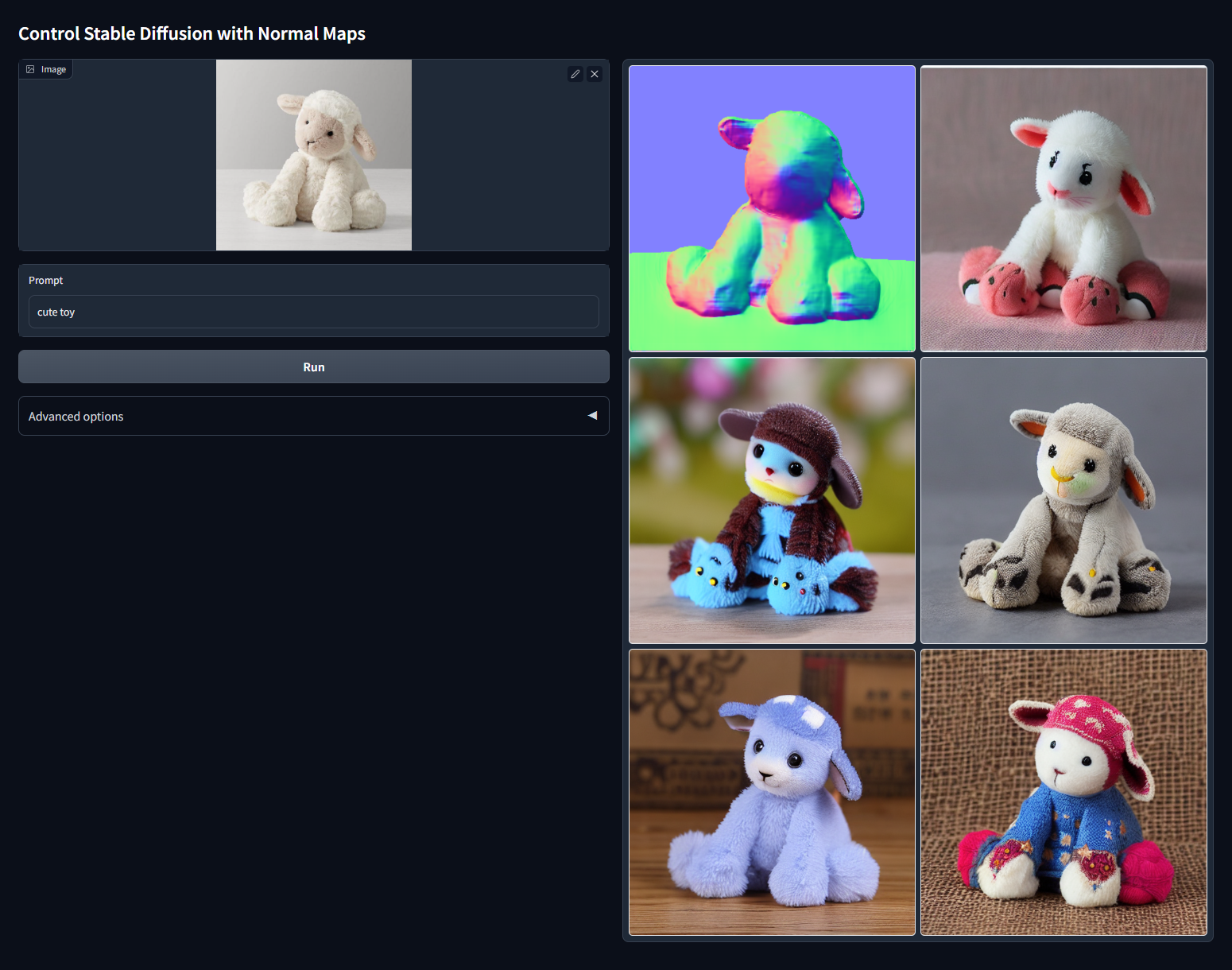
Модель Normal Map. Карта нормалей определяет положение объекта в трехмерном пространстве.
Подходит для генерации 3D-персонажей или реалистичных картинок.
Модель MLSD, Mobile Line Segment Detection. Детектор прямых линий.
Полезен для генерации картинок на основе изображений с прямыми линиями: дизайна интерьеров, зданий, уличных сцен.
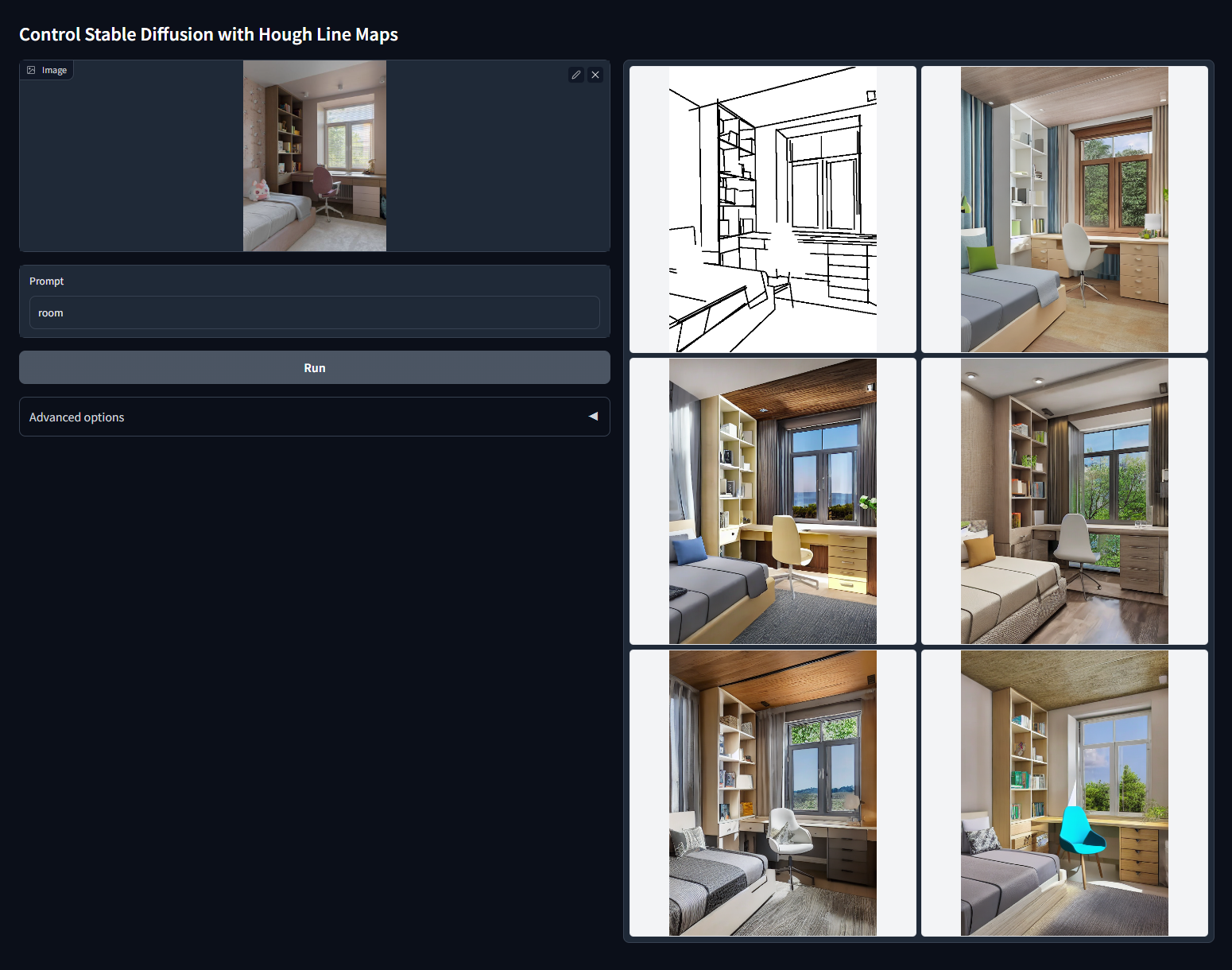
Модель OpenPose. Отлично работает с людьми на изображениях. При загрузке картинки определяет положение головы, плеч, рук, ног, а потом создает «скелет» — довольно точную схему позы. Если добавить текстовое описание, к примеру, поменять сыщика с референса на спасателя, то нейросеть изменит облик, но сохранит выбранную позу.
В модели есть редактор, где можно перетаскивать части тела и делать свои позы.
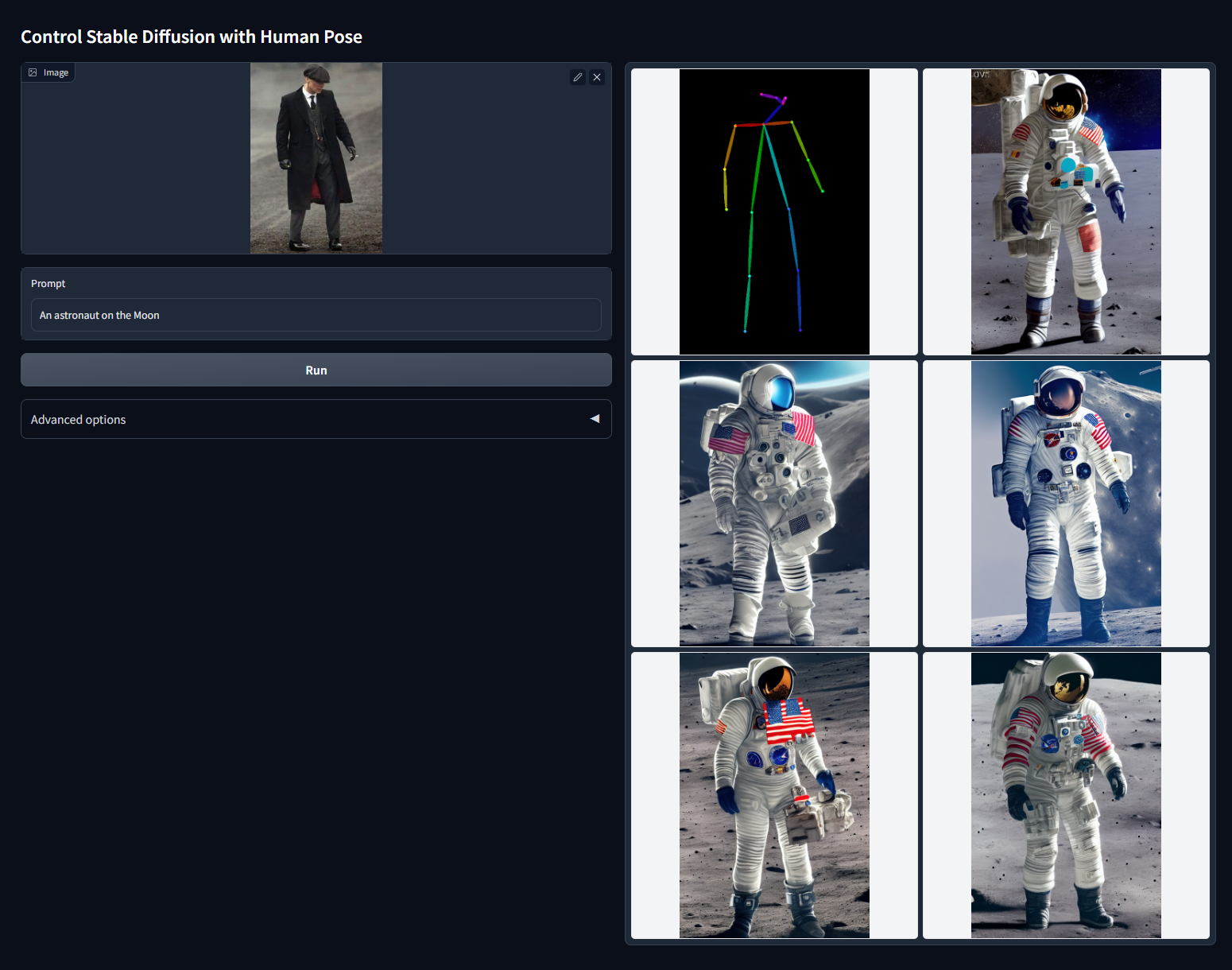
Модель Scribble. Генерирует картинку по скетчу. Достаточно сделать или загрузить рисунок, причем не нужно обладать талантом художника — хватит и примитивного наброска. А с помощью текста можно уже указать, во что превратить скетч.
Так можно воплощать идеи и эскизы.
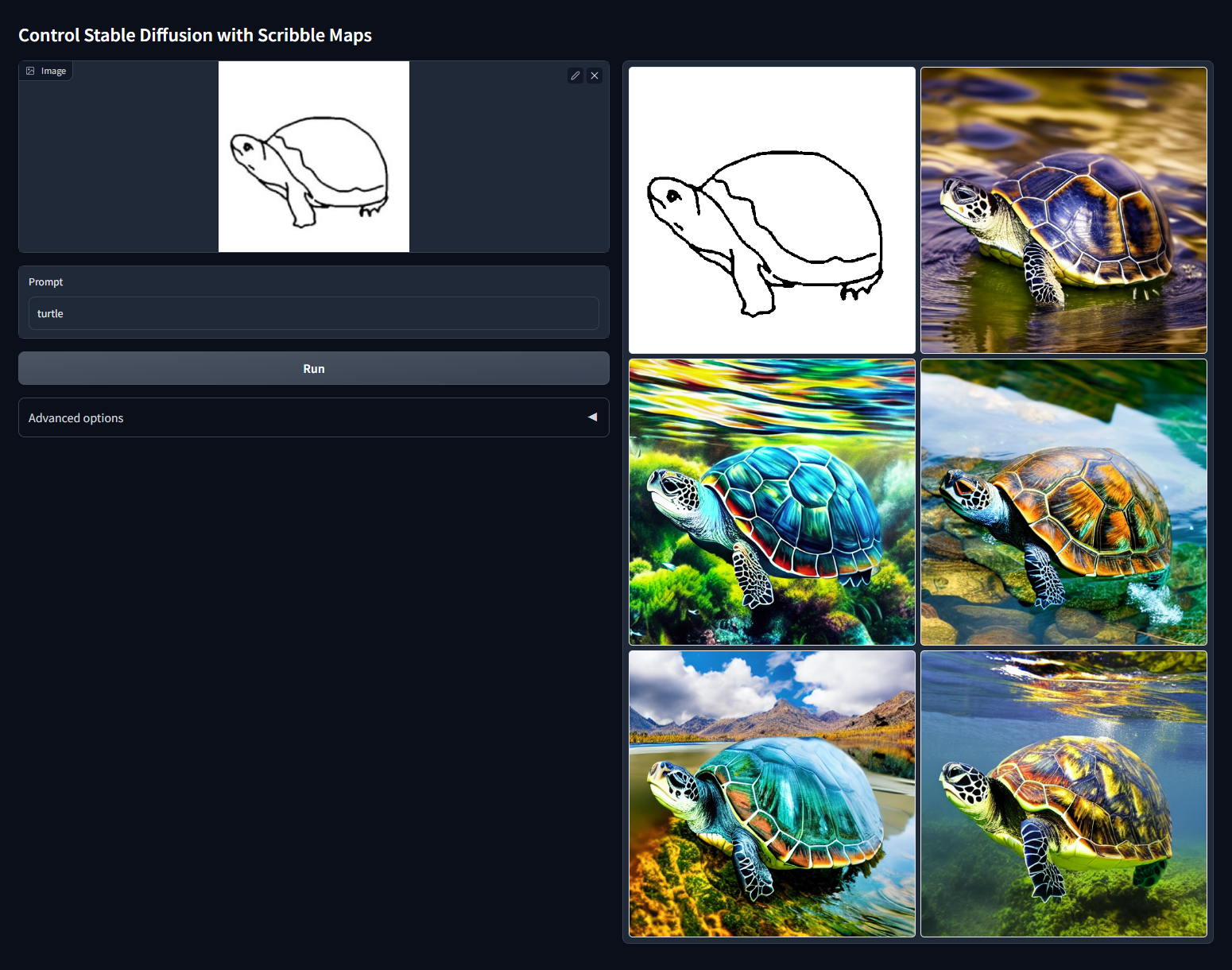
Как ControlNet изменяет картинки с сохранением черт оригинала
С этой задачей лучше остальных справляются три основные модели: Canny, Normal Map и Depth Map. Нельзя сказать, что какая-то из них лучше, потому что они работают по разным принципам. Их нужно выбирать в зависимости от референса и цели.
Для теста Canny выбрали фото Райана Гослинга и Марго Робби со съемок фильма «Барби» — попробуем его изменить. Модель тщательно учитывает детали: орнамент на одежде, выражение лица и даже текстуру дерева перед актерами. Но из-за такого внимания к мелким моментам бывают ошибки. Например, нейросеть «видела» в наброске не элементы одежды и фона, а другой силуэт, и поэтому генерировала дополнительное лицо.









Depth Map подходит для работы с глубиной — задним и передним планом. Это больше для пейзажей, архитектуры и композиций. Если хочется сгенерировать здание, но сохранить его основные части наподобие шпиля, то карта глубины справляется без проблем.
Для карты глубины взяли скриншот из Hogwarts Legacy. Игровой замок тут же потерял узнаваемость, но нейросеть сохранила масштабность постройки и учла пейзаж. В других тестах происходил тот же эффект, потому что карта глубины не прорисовывает мелкие детали.









Normal Map создает карту, которую еще используют в 3D-редакторах для имитации геометрии на объектах. Например, текстура нормалей человеческой кожи покажет углубления, поры и царапины. Это удобно, если надо сгенерировать персонажа и сохранить геометрические особенности — броню, выпуклые части или несовершенства.
Для карты нормалей взяли кадр из того самого диалога о симфониях и картинах фильма «Я, робот». Здесь нейросеть учла детали — провода, форму тела и разницу материалов. При работе с картами нормалей можно настроить, как будет обрезаться фон, так что это удобный инструмент для концепт-артистов.










Как ControlNet сохраняет позу
Для проверки этого метода мы взяли танец Хоакина Феникса в «Джокере». Поза сложная, но алгоритм ее воссоздал — пусть и без харизмы актера: в отличие от той же модели Canny, OpenPose даже не пытается сохранить одежду, черты лица и другие визуальные элементы оригинала. Только воссоздать позу.
При этом OpenPose работает не везде. Например, если на картинке-референсе люди перекрывают друг друга, то части тела в скелете исчезают.
У OpenPose есть уникальное преимущество — возможность выстроить позу самому. Для этого уже есть отдельные плагины в дополнение к основному ControlNet: двигаешь кости на черном фоне как хочешь, а если надо, то добавляешь еще скелеты. Так можно сгенерировать персонажа в любом виде — или сразу в нескольких.











Как ControlNet генерирует картинки по скетчу
В ControlNet можно загрузить набросок от руки и сгенерировать по нему что угодно. Если честно, пока это работает не очень хорошо: нейросеть часто упускает детали и слишком жестко следует общему контуру, а значит, и анатомическим ошибкам художника. То есть в теории скетч и может нарисовать кто угодно, но каждая кривая линия сильно влияет на результат.
На эту часть эксперимента ушло больше всего времени: нарисовали около пяти иллюстраций, но только по одной получили качественные генерации.





Сначала мы нарисовали длиннохвостого кота на ноутбуке, но нейросеть отказывалась генерировать клавиатуру, даже если указать это в текстовом запросе. Получается, нужно добавить кнопки на скетч. Но гораздо легче сделать коллаж из фотографий кота и клавиатуры и сгенерировать картинку уже в модели Canny.
В других же случаях сервис не учитывал позу или эмоцию. Это делает Scribble скорее бесполезным инструментом: нужно прорабатывать скетч больше, но тогда легче генерировать другими способами. По наброску с роботом мы генерировали десятки раз, но все они выглядели плохо.


Как ControlNet генерирует на основе гифок
Для теста взяли ролик с актером Шайа Лабафом. Нейросети не умеют делать плавную анимацию, потому что каждый следующий кадр генерируют отдельно от предыдущего. Из-за этого одна и та же деталь постоянно меняется.
В текстовом поле описали мужчину, одежду, часы на руках. Даже при использовании ControlNet плавности недостаточно, поэтому такие анимации подойдут только для соцсетей и чего-то экспериментального. В паре кадров видно, как нейросеть рисует круглые часы, ошибается в положении рук и даже теряет тон кожи.


На основе Stable Diffusion есть новый инструмент — Gen-1. Разработчики попытались добиться консистентной анимации, но недостатки все равно видны. Это все равно яркий признак, что в индустрии работают в эту сторону: наверняка через десять лет появятся нейросети и под эту задачу.
Сейчас есть только одно применение — в экспериментальной анимации. Альберто Миелго, который занимался стилем мультфильма «Человек-паук: Через вселенные», часто вставляет кадры с абсолютно другой стилистикой. Это помогает здорово оживить анимацию, а с ControlNet делать такое проще и быстрее.

Где попробовать ControlNet самому
Установить ControlNet самостоятельно. Полная версия со всеми моделями скачивается и устанавливается как расширение к основной нейросети Stable Diffusion. Так у вас будет постоянный доступ к моделям и все возможности сервиса. Оригинальный репозиторий выложен на GitHub. Подходит для тех, у кого есть мощный ПК и минимальные навыки программирования.
Пользователи уже создали простое расширение для Stable Diffusion, которое можно установить без навыков программирования. Нужно:
- Скачать модели для ControlNet. Можно выбрать отдельные или скачать все сразу.
- Если вы пользуетесь Stable Diffusion, вероятно, у вас уже есть веб-интерфейс Automatic1111. Если нет, установите его, выбрав свою операционную систему: Windows с процессорами Nvidia, Windows с процессорами AMD, Linux или MacOS.
- Включите WebUI и установите расширение ControlNet. Для этого кликните на вкладку Extensions и нажмите Install from URL. Скопируйте в поле эту ссылку и нажмите Install.
- Добавьте модели с расширением.safetensor в папку stable-diffusion-webui\extensions\sd-webui-controlnet\models.
- У ControlNet нет собственной вкладки в Automatic1111. Вместо этого она будет отображаться как отдельный раздел в нижней части вкладок txt2img или img2img.
- Перетащите картинку из браузера или с рабочего стола и начинайте генерировать.


Воспользоваться онлайн-инструментами. Урезанные версии ControlNet доступны прямо в браузере. Они позволяют понять принципы работы нейросети, но качественные картинки тут вряд ли получится сгенерировать.
Scribble Diffusion. Простая модель Scribble, которая генерирует картинки по наброску. Делаете скетч прямо в браузере, прописываете текстовый запрос и нажимаете кнопку «сгенерировать».



Демо на Hugging Face. На платформе можно протестировать все основные модели ControlNet, а не только Scribble. Загружаете исходную картинку, прописываете текстовый запрос и генерируете.
На выходе получается соответствующий заявленной модели результат, но с артефактами и кривыми лицами у персонажей.

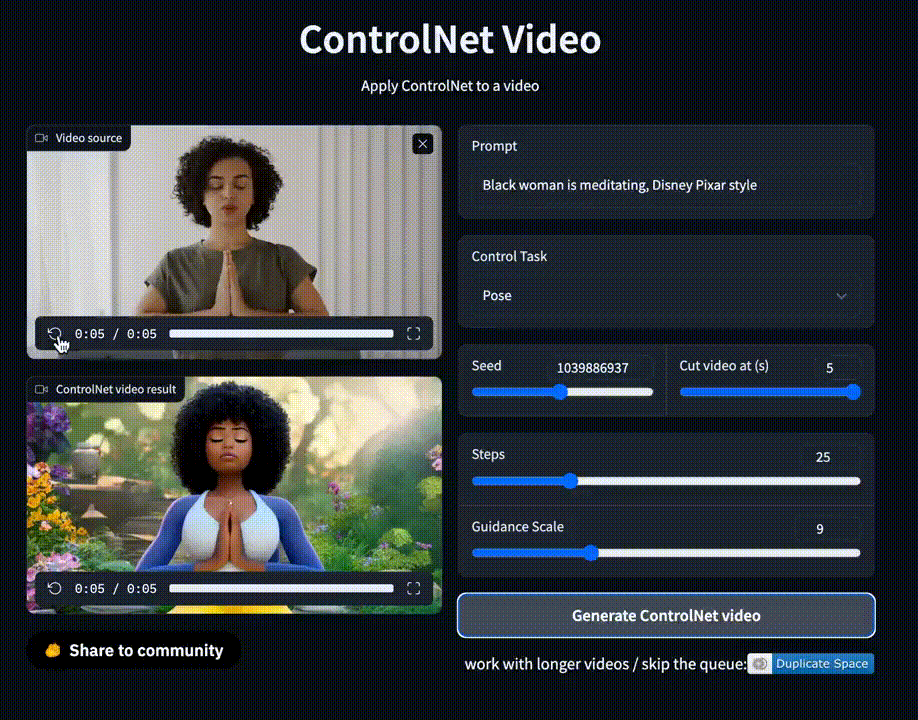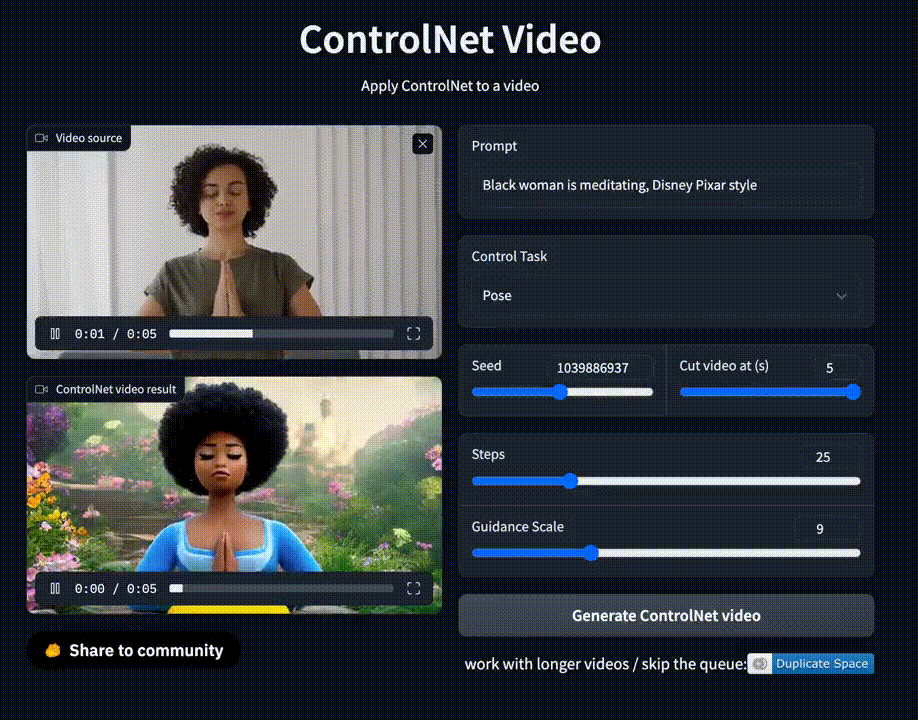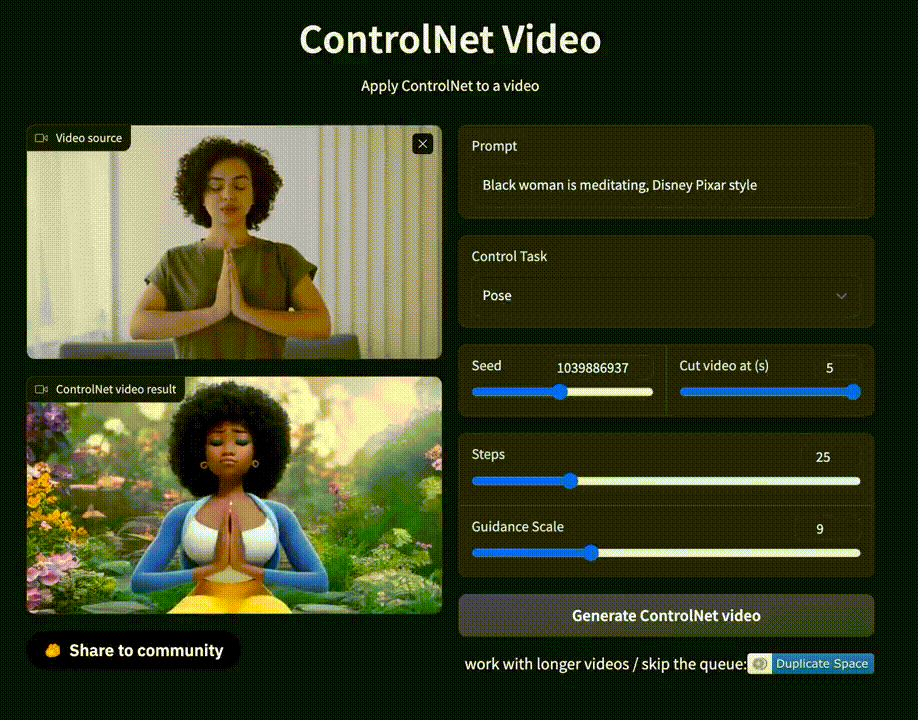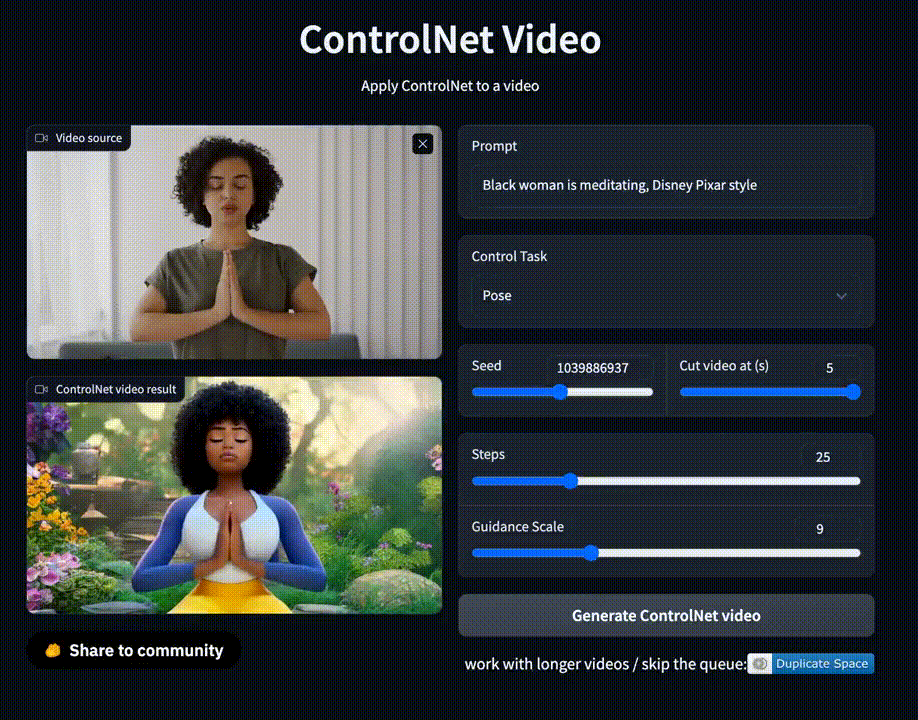
На площадке также есть демо для генерации видео, которое позволяет сгенерировать короткий ролик на основе гифки и текстового запроса.
Однако ожидание очень долгое, а сервис порой выдает ошибку.
Мы постим кружочки, красивые карточки и новости о технологиях и поп-культуре в нашем телеграм-канале. Подписывайтесь, там классно: @t_technocult.





















